vLLM x AMD: Efficient LLM Inference on AMD Instinct™ MI300X GPUs
Dec 12, 2024
- Part 1
- Part 2
- Part 3
- Part 4
Overview
As generative AI continues to advance, efficiently serving Large Language Models (LLMs) on GPUs has become essential for inference workloads. However, users continue to face compute-bound or memory-bound challenges. To address these challenges and deliver superior performance with AMD InstinctTM GPUs, AMD has adopted vLLM as the major serving framework. This open-source library enhances the serving and execution of LLMs with high throughput and memory efficiency. Additionally, the recent announcement of vLLM as the latest incubation project by Linux Foundation AI & Data underscores its tremendous value and potential impact on the AI and data science community.
To fully harness the potential of vLLM on AMD Instinct™ MI300X GPUs, it’s essential to dive deeper into key techniques and their practical implications. In Part 2, we explore Chunked Prefill, a method that optimizes memory usage for efficient inference. Part 3 unpacks Speculative Decoding, a groundbreaking approach that accelerates large language model (LLM) outputs. Finally, Part 4 serves as a comprehensive Implementation Guide and Roadmap, equipping you with actionable insights for successful deployment.
What is Prefix Caching?
Prefix caching is a specialized caching technique primarily used in language models to optimize the generation of text. Specifically designed for tasks involving language models, this method includes caching the model outputs for previously processed input sequences. This approach has been proved particularly beneficial in scenarios where there is a need to generate text based on varying prompts or to continue from previous outputs without the re-computation of all data.
When to Apply Prefix Caching?
Prefix caching provides advantages for interactive applications such as chatbots and language models in general. It improves performance and user experience in the following ways:
1. Reduced Latency: By caching the results of previously computed prefixes, the model can avoid redundant calculations, leading to faster response times.
2. Context Preservation: In scenarios where context is important, prefix caching allows the model to recall prior interactions more efficiently.
3. Resource Efficiency: By reusing computations for similar prompts, prefix caching reduces the overall computational load on GPU resources, and it results in costs savings.
4. Improved User Experience: Users could get faster and smoother responses, this is particularly important in customer support or conversational agents where response time can impact user satisfaction.
5. Long Conversations: For scenarios like virtual assistants, where multi-turn dialogues are needed, they are usually with longer conversations, prefix caching can effectively handle the increasing complexity and depth of context without degrading in performance.
5X Speed Up: Significant Latency Reduction with Prefix Caching
To demonstrate how fast it could be when running on AMD MI300X GPUs, we used Llama3.1-70B and Llama3.1-405B models as examples. When enabling prefix caching, the performance boost is evident, as shown in Figure 1. Let’s explore the benefits of this feature from the perspective of latency and throughput.
For the Llama3.1-70B model, enabling automatic prefix caching significantly reduces the P99 request latency, which results in a speedup of about 1.3X ~ 5.4X and is extremely useful for the long sequence length scenarios. For example, the latency has been reduced from 144s to 26s for the 16K sequence length case thus enhancing the user experience.
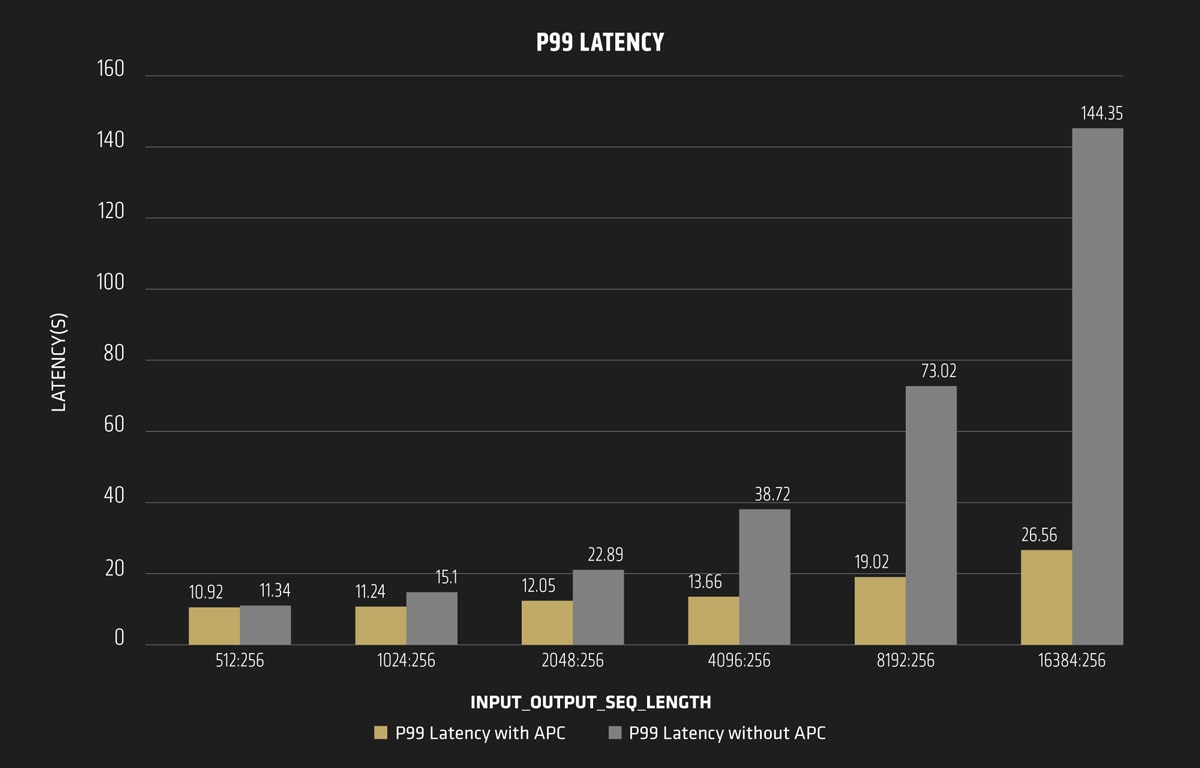
Tips: P99 latency is a performance metric used to measure the latency of a system. Specifically, it represents the time it takes for 99% of data packets or requests to be processed. It’s widely used by internet service providers to assess the user experience for internet applications.
Enhanced Throughput with Prefix Caching
In this instance, to verify the throughput variations, we adjusted the input sequence length dynamically to explore its impact by enabling or disabling the automatic prefix caching (APC). Regarding the tokens per second, the higher, the better!
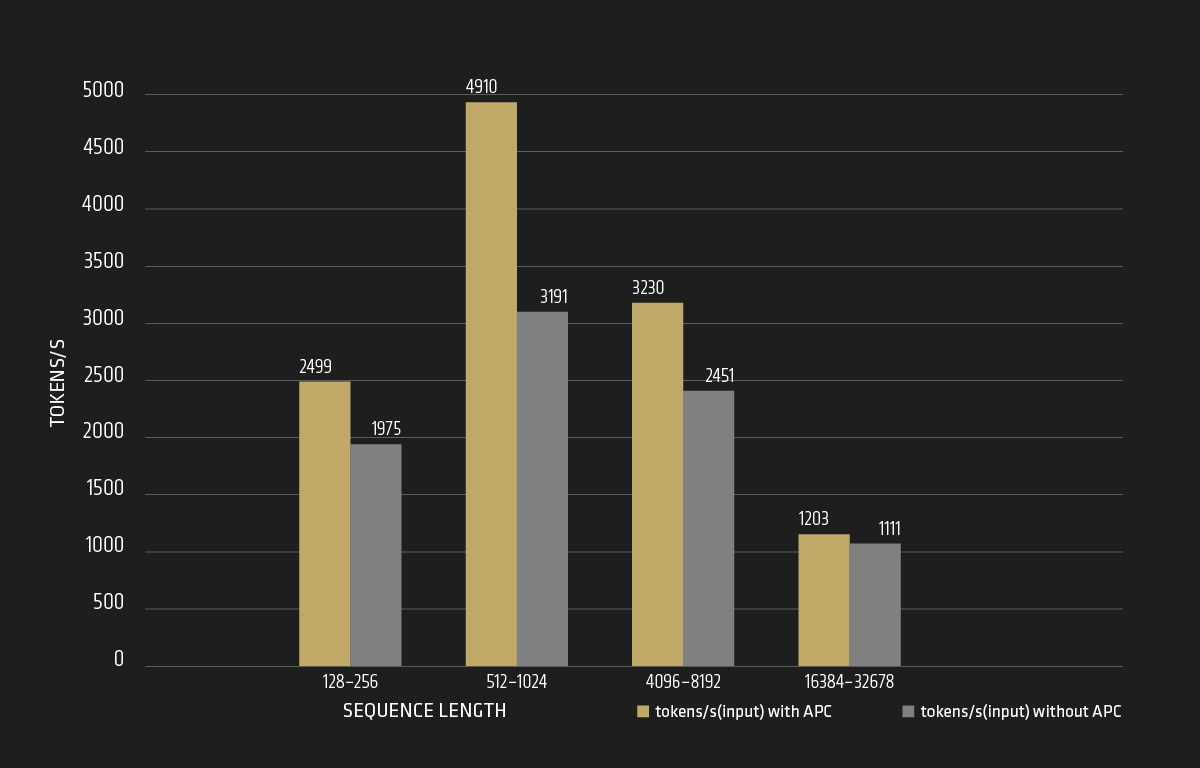
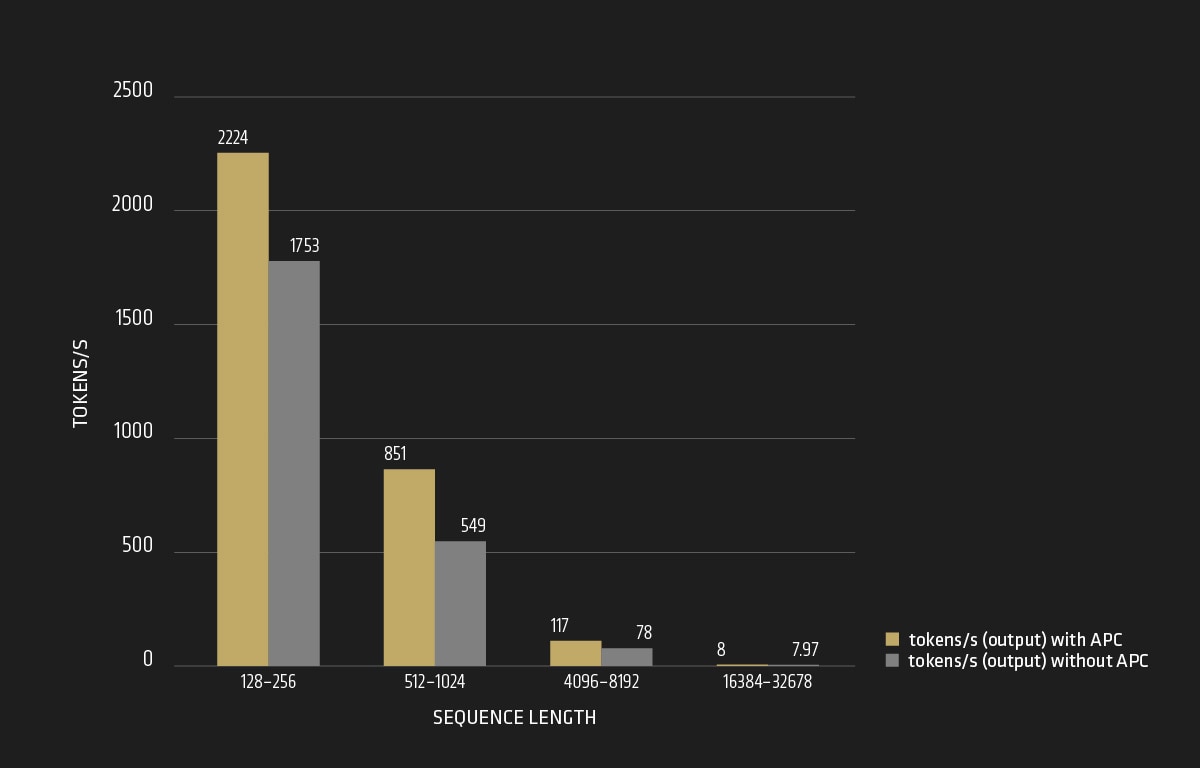
For Llama3.1-70B model, we have observed the following findings across different ranges of input sequence length, as shown in Figure 2 and Figure 3:
- Input Tokens Per Second: The number of input tokens per second increases significantly with APC enabled, especially within the sequence length range of 128 to 8192. However, for very long sequence lengths, the tokens per second initially increase and then decrease considerably with APC. It requires more KV cache memory space or special optimizations to better handle the long sequence length scenarios.
- Output Tokens Per Second: The output tokens per second also increase with APC enabled, particularly within the range of 128 to 4096 sequence length, showing higher throughput compared to when APC is not applied.
The APC appears to provide higher tokens per second for smaller sequence length but becomes less efficient for larger sequence length. Without APC, the tokens per second are more stable across different sequence lengths, though generally lower than with APC for smaller sequence length.
Conclusion
Overall, prefix caching in language models enhances efficiency, responsiveness, and the overall quality of interactions in applications such as chatbots and other conversational interfaces. We will further explore the performance improvements using chunked prefill and speculative decoding, providing step-by-step guidance and outlining the roadmap in future blogs. To explore how chunked prefill significantly boosts the performance of language models on AMD GPUs, read vLLM x AMD: Efficient LLM Inference on AMD Instinct™ MI300X GPUs (Part 2) .
Footnotes
MI300-066:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model P99 request latency with and without automatic prefix caching. The data type is FP16 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input_output_sequence_length 512-256 | with APC tokens/s: 10.92 | without APC tokens/s: 11.34;
Input_output_sequence_length 1025-256 | with APC tokens/s: 11.24 | without APC tokens/s: 15.1 | ratio – 1.3X;
Input_output_sequence_length 2014-256 | with APC tokens/s: 12.05 | without APC tokens/s: 22.89 | ratio – 1.9X;
Input_output_sequence_length 4096-256 | with APC tokens/s: 13.66 | without APC tokens/s: 38.72 | ratio – 2.8X;
Input_output_sequence_length 8192-256 | with APC tokens/s: 19.02 | without APC tokens/s: 73.02 | ratio – 3.8X;
Input_output_sequence_length 16384-256 | with APC tokens/s: 25.56 | without APC tokens/s: 144.35 | ratio – 5.6X.
Performance may vary based on different hardware configurations, software versions and optimization.
MI300-067:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model input tokens per second when automatic prefix caching (APC) enabled or not enabled. The data type is FP16 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input Sequence Length Range128-256 | with APC 2499 | without APC 1975
Input Sequence Length Range 512-1024 | with APC 4910 | without APC 3191
Input Sequence Length Range 4096-8192 | with APC 3230 | without APC 2451
Input Sequence Length Range 16384-32678 | with APC 1203 | without APC 1111
Performance may vary based on different hardware configurations, software versions and optimization.
MI300-068:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model output tokens per second when automatic prefix caching (APC) enabled or not enabled. The data type is FP16 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Output Sequence Length Range 128-256 | with APC tokens/s: 2224 | without APC tokens/s: 1753
Output Sequence Length Range 512-1024 | with APC tokens/s: 851 | without APC tokens/s: 549
Output Sequence Length Range 4096-8192 | with APC tokens/s: 117 | without APC tokens/s: 78
Output Sequence Length Range 16384-32678 | with APC tokens/s: 8 | without APC tokens/s: 7.97
Performance may vary based on different hardware configurations, software versions and optimization.
Footnotes
MI300-066:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model P99 request latency with and without automatic prefix caching. The data type is FP16 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input_output_sequence_length 512-256 | with APC tokens/s: 10.92 | without APC tokens/s: 11.34;
Input_output_sequence_length 1025-256 | with APC tokens/s: 11.24 | without APC tokens/s: 15.1 | ratio – 1.3X;
Input_output_sequence_length 2014-256 | with APC tokens/s: 12.05 | without APC tokens/s: 22.89 | ratio – 1.9X;
Input_output_sequence_length 4096-256 | with APC tokens/s: 13.66 | without APC tokens/s: 38.72 | ratio – 2.8X;
Input_output_sequence_length 8192-256 | with APC tokens/s: 19.02 | without APC tokens/s: 73.02 | ratio – 3.8X;
Input_output_sequence_length 16384-256 | with APC tokens/s: 25.56 | without APC tokens/s: 144.35 | ratio – 5.6X.
Performance may vary based on different hardware configurations, software versions and optimization.
MI300-067:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model input tokens per second when automatic prefix caching (APC) enabled or not enabled. The data type is FP16 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input Sequence Length Range128-256 | with APC 2499 | without APC 1975
Input Sequence Length Range 512-1024 | with APC 4910 | without APC 3191
Input Sequence Length Range 4096-8192 | with APC 3230 | without APC 2451
Input Sequence Length Range 16384-32678 | with APC 1203 | without APC 1111
Performance may vary based on different hardware configurations, software versions and optimization.
MI300-068:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model output tokens per second when automatic prefix caching (APC) enabled or not enabled. The data type is FP16 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Output Sequence Length Range 128-256 | with APC tokens/s: 2224 | without APC tokens/s: 1753
Output Sequence Length Range 512-1024 | with APC tokens/s: 851 | without APC tokens/s: 549
Output Sequence Length Range 4096-8192 | with APC tokens/s: 117 | without APC tokens/s: 78
Output Sequence Length Range 16384-32678 | with APC tokens/s: 8 | without APC tokens/s: 7.97
Performance may vary based on different hardware configurations, software versions and optimization.
Overview
In the previous blog, we learned that prefix caching significantly enhances the efficiency and throughput of language models, particularly for smaller sequence lengths. With APC (Advanced Prefix Caching) enabled, the number of input and output tokens per second increases notably, especially within the sequence length range of 128 to 8192 for input and 128 to 4096 for output.
This blog will explore how chunked prefill significantly boosts the performance of language models on AMD GPUs. By breaking down input sequences into smaller chunks and pre-computing outputs, chunked prefill enhances both efficiency and coherence in text generation tasks.
What is Chunked Prefill?
Chunked prefill is a technique often used in language modeling and text generation to improve the efficiency and coherence of generated outputs.
Specifically, Chunking means that the input text is divided into smaller, manageable segments or "chunks". Instead of processing an entire long sequence of text simultaneously, the model handles these chunks individually.
Prefill refers to the model’s ability to pre-compute or cache outputs for these chunks, enabling faster generation when similar or overlapping input sequences are encountered.
When to Apply Chunked Prefill
Chunked prefill is particularly useful in scenarios where there are multiple concurrent requests happen, for example:
Interactive Applications: Chunked prefill can be applied in chatbots or virtual assistants where conversations can be segmented into manageable sections.
Content Generation: In applications like automated writing or summarization, chunked prefill can indirectly benefit the user experience by providing faster and more consistent responses, which can be crucial in real-time applications. By segmenting the prefill into smaller, manageable chunks, each segment can generate with the right context, thereby improving the overall quality of the output.
Benefits of Chunked Prefill
Higher Efficiency: By processing smaller chunks, the model can utilize cached outputs for previously computed segments, reducing computation time for similar prompts.
Better Memory Management: Handling smaller segments can help manage memory more effectively in environments with limited resources or when dealing with long contexts.
Improved Coherence: Chunked processing can help maintain coherence in generated text by allowing the model to focus on relevant segments without getting overwhelmed by lengthy inputs.
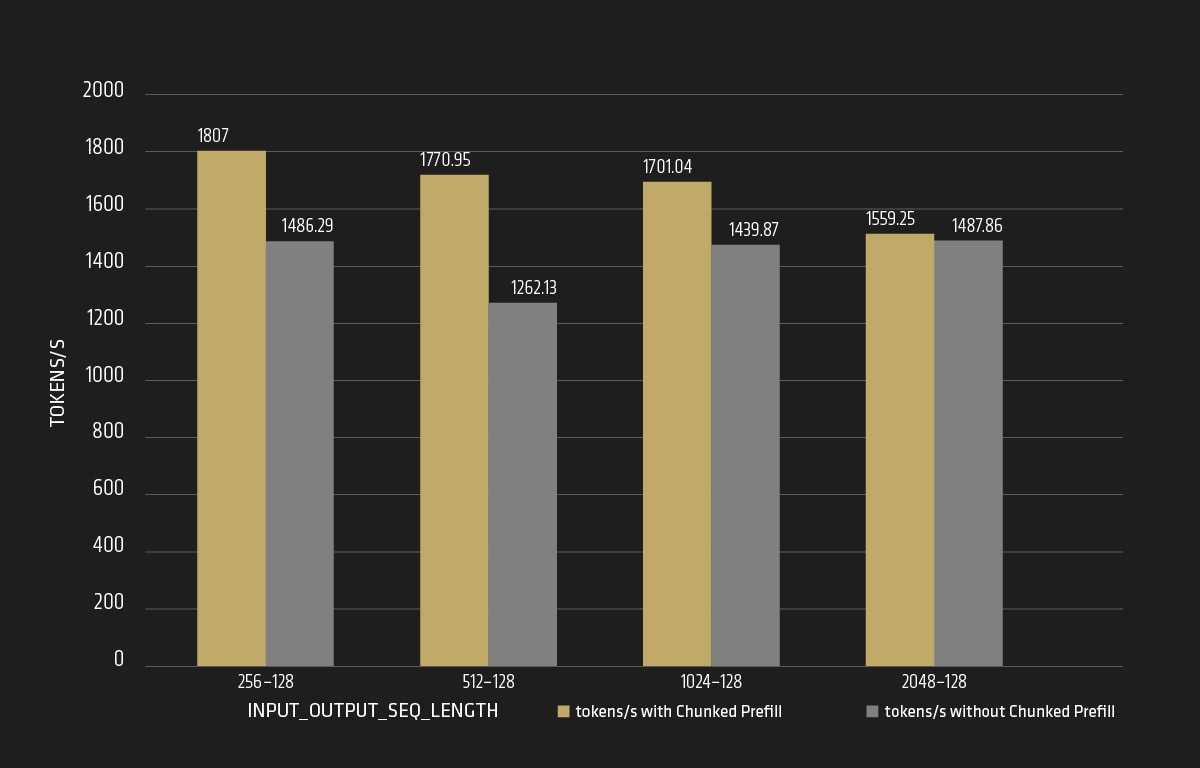
Boosting Throughput with Chunked Prefill
The chart below demonstrates the performance of the Llama3.1-70B model using chunked prefill at different sequence lengths. The main finding is that the average request throughput speedup is between 1.05X and 1.4X. This indicates significant efficiency improvements in text generation, highlighting the benefits of chunked prefill in enhancing model performance, particularly for high throughput and efficient memory management.
Effects of max_num_batched_tokens
In vLLM, max_num_batched_tokens refers to the maximum number of tokens that can be processed in a single batch. By default, this value is set as 512. Adjusting this parameter can significantly impact the performance of the model in various ways:
- Inter-Token Latency (ITL): Smaller values for max_num_batched_tokens generally result in better ITL because there are fewer prefills interrupting the decoding process.
- Throughput: Larger values for max_num_batched_tokens can improve throughput by allowing more tokens to be processed in each batch.
- Time to First Token (TTFT): Higher values for max_num_batched_tokens can also improve TTFT by batching more prefill requests together.
- Memory Utilization: Adjusting max_num_batched_tokens affects how GPU memory is utilized. Higher values may require more memory, so it’s important to balance this with the available resources to avoid preemptions and recomputations.
- Value Adjustment:
- Higher Values: Increase throughput by allowing more tokens to be processed in parallel but may increase latency if memory is insufficient.
- Lower Values: Improve ITL (Inter-Token Latency) by reducing interruptions during decoding but may decrease throughput.
In summary, tuning max_num_batched_tokens parameter allows the optimization of the model performance to meet specific requirements, whether it involves reducing latency, increasing throughput, or balancing memory usage.
When chunked prefill is enabled, the scheduling policy prioritizes decode requests. It batches all pending decode requests before scheduling any prefill. If a prefill request cannot fit into the max_num_batched_tokens, it is chunked.
Performance Test with Variable max_num_batched_tokens
According to the official vLLM user guide, users can tune the performance by adjusting the max_num_batched_tokens. As mentioned above, it is set to be 512 by default, but its suitability for MI300X GPU is uncertain, so we decided to run the experimental test to verify. The test has been conducted on AMD Instinct™ MI300X accelerator, with ROCmTM software 6.2, AMD EPYC 9654 96-Core CPU processor, and Ubuntu 22.04.4 LTS.
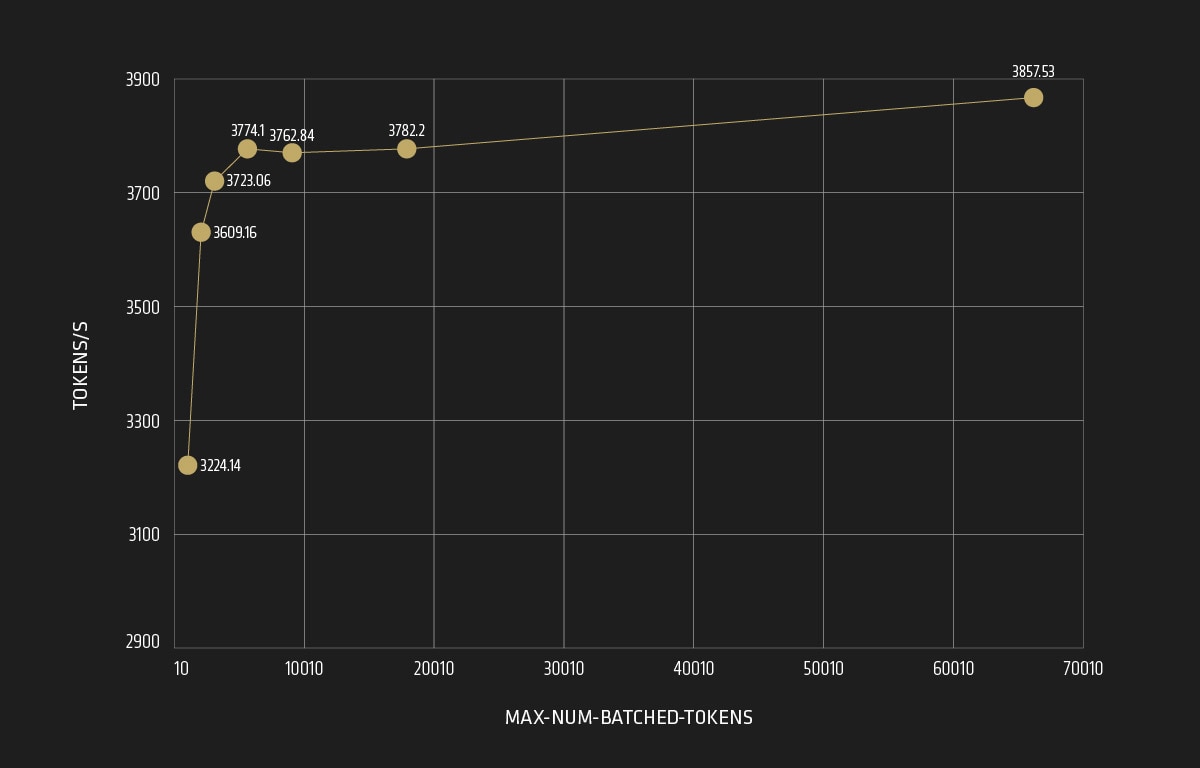
As shown in Figure 5:
- Throughput increases from 2373 to 3774 tokens/s as max_num_batched_tokens varies from 256 to 4096.
- Throughput stabilizes and does not significantly increase beyond 4096 max_num_batched_tokens.
- Optimal throughput is achieved when max_num_batched_tokens is set to greater than 2048.
- Users need to determine the proper value for max_num_batched_tokens based on their application scenario to avoid performance degradation.
It can be concluded that for each application scenario, users need to determine the proper value of this feature when applied, because both smaller and larger number would result in performance degradation. It is recommended to set it as > 2048 for optimal throughput.
Latency Analysis
In this analysis, we compared the performance variations by enabling and disabling chunked prefill under different input and output sequence length conditions. For latency, the lower, the better!
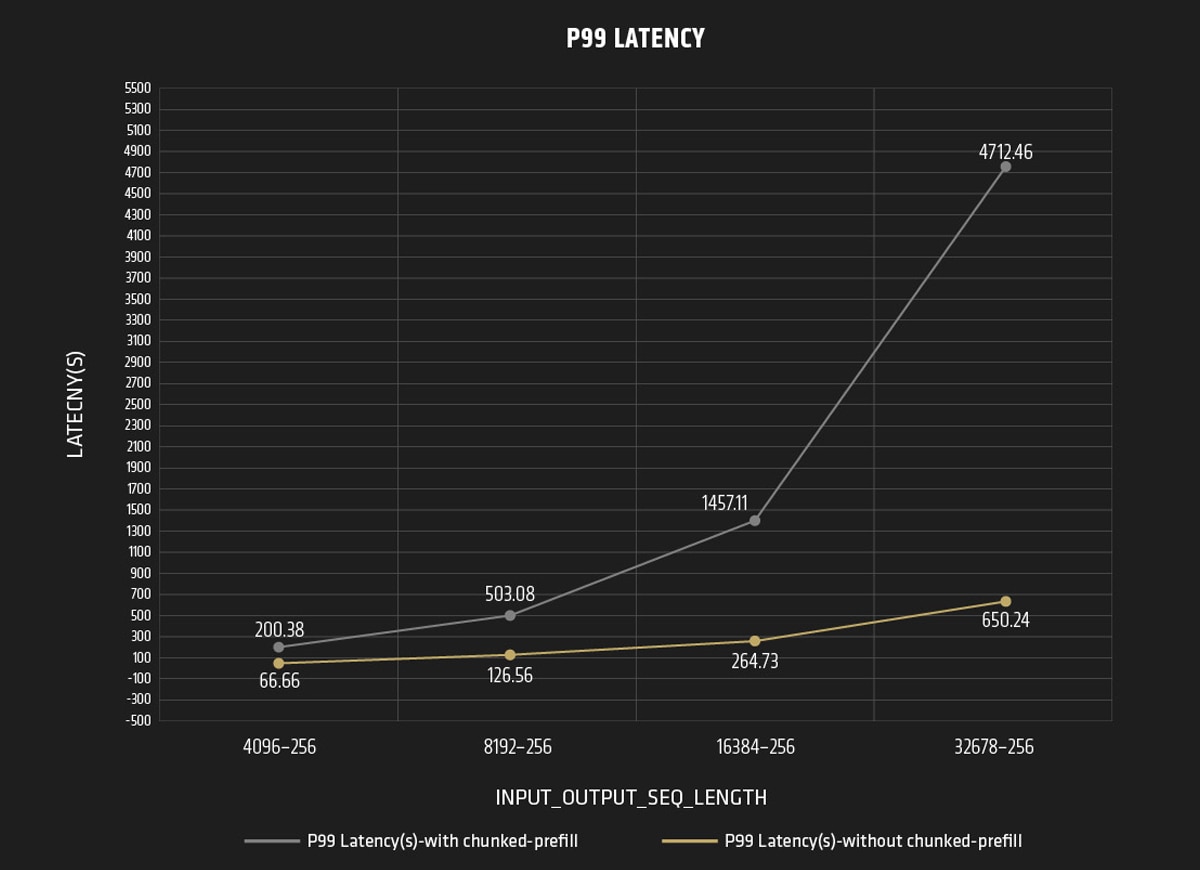
With Chunked Prefill
The P99 Latency increases significantly as the in_out_seq_length increases.
Without Chunked Prefill
The P99 Latency also increases with the in_out_seq_length; however, the values are significantly lower compared to the chunked prefill scenario.
Overall, the P99 Latency increases with the in_out_seq_length in both scenarios, but the increase is much more pronounced with using chunked prefill. Without chunked prefill, the latency values are notably lower and increase at a more gradual rate. In summary, the chunked prefill feature may lead to increased latency under specific conditions, particularly when the system configuration and workload are not optimally balanced. Here are some scenarios where latency might increase:
Insufficient GPU Memory
If the GPU memory is not sufficient to handle the larger batch sizes created by chunked prefill, it can lead to frequent preemptions and recomputations. This overhead can increase the end-to-end latency.
High Preemption Rate
When the system frequently encounters preemptions due to insufficient KV cache space, the recomputation of pre-empted requests can adversely affect latency. This is more likely to happen if the gpu_memory_utilization is set too low.
Suboptimal max_num_batched_tokens
Setting the max_num_batched_tokens too high can lead to inefficient GPU utilization and increased latency.
Large Model Sizes
For very large models, the overhead of managing multiple smaller chunks can become significant, leading to increased latency.
To mitigate these issues, it's crucial to tune the parameters such as gpu_memory_utilization, max_num_batched_tokens, and tensor_parallel_size based on your specific hardware and workload. Proper tuning can help achieve a balance between throughput and latency, ensuring optimal performance.
Conclusion
In part 2 of the AMD vLLM blog series, we delved into the performance impacts of using vLLM chunked prefill for LLM inference on AMD GPUs. Our findings indicated that while chunked prefill can lead to significant latency increases, especially under conditions of high preemption rates or insufficient GPU memory, careful tuning of system parameters can help mitigate these issues. By optimizing settings such as gpu_memory_utilization, max_num_batched_tokens, and tensor_parallel_size, we can strike a better balance between throughput and latency, ensuring more efficient performance.
As we continue our exploration of advanced vLLM techniques for enhanced LLM performance on AMD GPU, part 3 will introduce the feature of speculative decoding.
Overview
Part 1 and Part 2 of the AMD vLLM blog series discussed vLLM features such as prefix caching, chunked prefill and tuning system parameters to optimize performance. We now introduce speculative decoding. This innovative technique further enhances language model performance on AMD GPUs by significantly speeding up the text generation process.
What is Speculative Decoding?
Speculative decoding is a technique used in natural language processing and text generation, designed to improve the efficiency and quality of generated text through predictions of future tokens. This technique is commonly utilized in scenarios such as:
Prediction of Future Tokens: speculative decoding involves generating a sequence of tokens in a way that allows the model to explore multiple potential continuations of a given input. Instead of producing one token at a time, the model speculates on what might come next.
Parallel Processing: By generating multiple possible continuations in parallel, the model can quickly assess several options before finalizing the output.
When to Apply Speculative Decoding?
You can apply speculative decoding to various application use cases. Let’s take the following as examples:
- Chatbots and Conversational Agents: Speculative decoding can enhance the responsiveness and relevance of responses by generating multiple potential replies and selecting the best one.
- Content Creation: This technique is useful in automated writing tools where generating coherent and engaging text is crucial.
Significant Latency Reduction and Enhanced Performance with Speculative Decoding
The benefits of speculative decoding lie in its ability to substantially reduce the latency and enhance performance of text generation models. This section highlights some of the key benefits that this technique brings to natural language processing tasks.
- Faster Generation: This method can significantly speed up text generation by evaluating multiple possibilities simultaneously, thereby reducing the time needed for serial token generation.
- Enhanced Coherence and Quality: By taking various continuations into account, the model is able to select the most contextually appropriate or relevant output, resulting in more coherent and higher-quality text.
- Exploration of Creativity: In creative writing applications, speculative decoding facilitates the exploration of diverse narrative paths or responses, thereby enriching the richness of creative output.
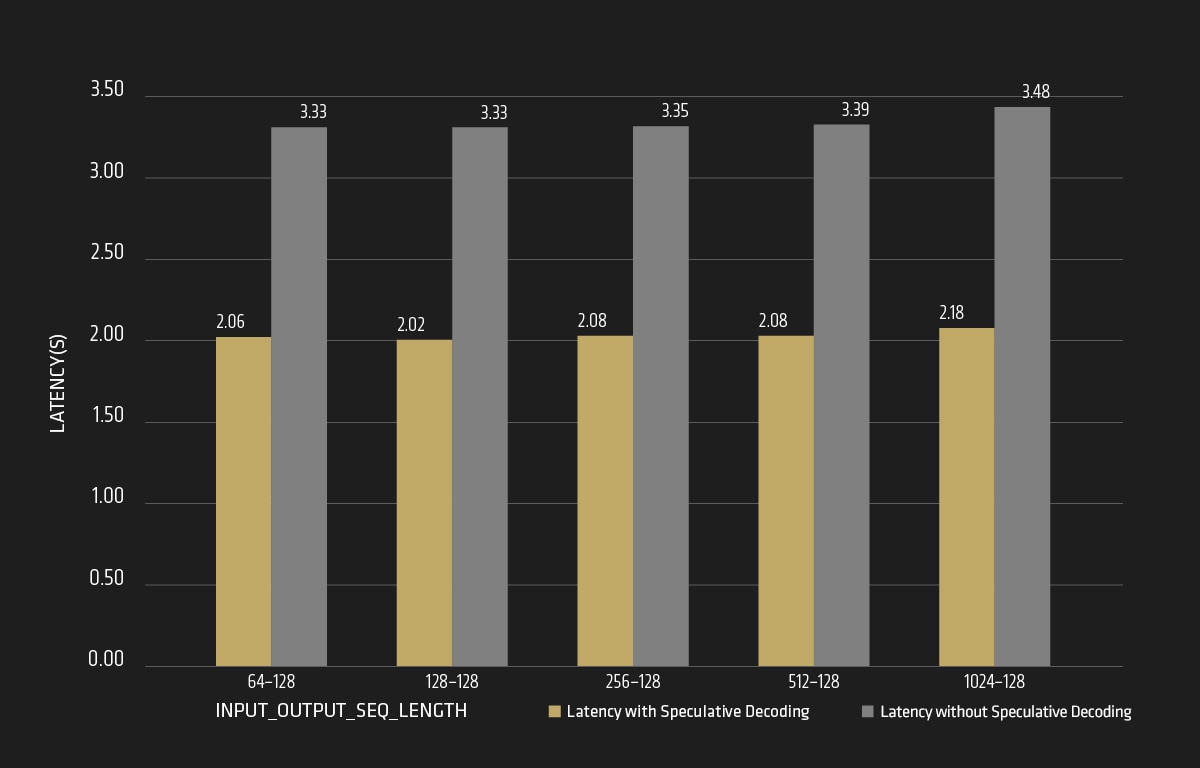
As shown in Figure 7, for the amd/Llama-3.1-70B-Instruct-FP8-KV model selected, by using the amd/Llama-3.1-8B-Instruct-FP8-KV as its corresponding speculative model, the average request latency declines from 3.3 to 2 seconds, achieving about 1.65X speedup when speculative decoding is enabled.
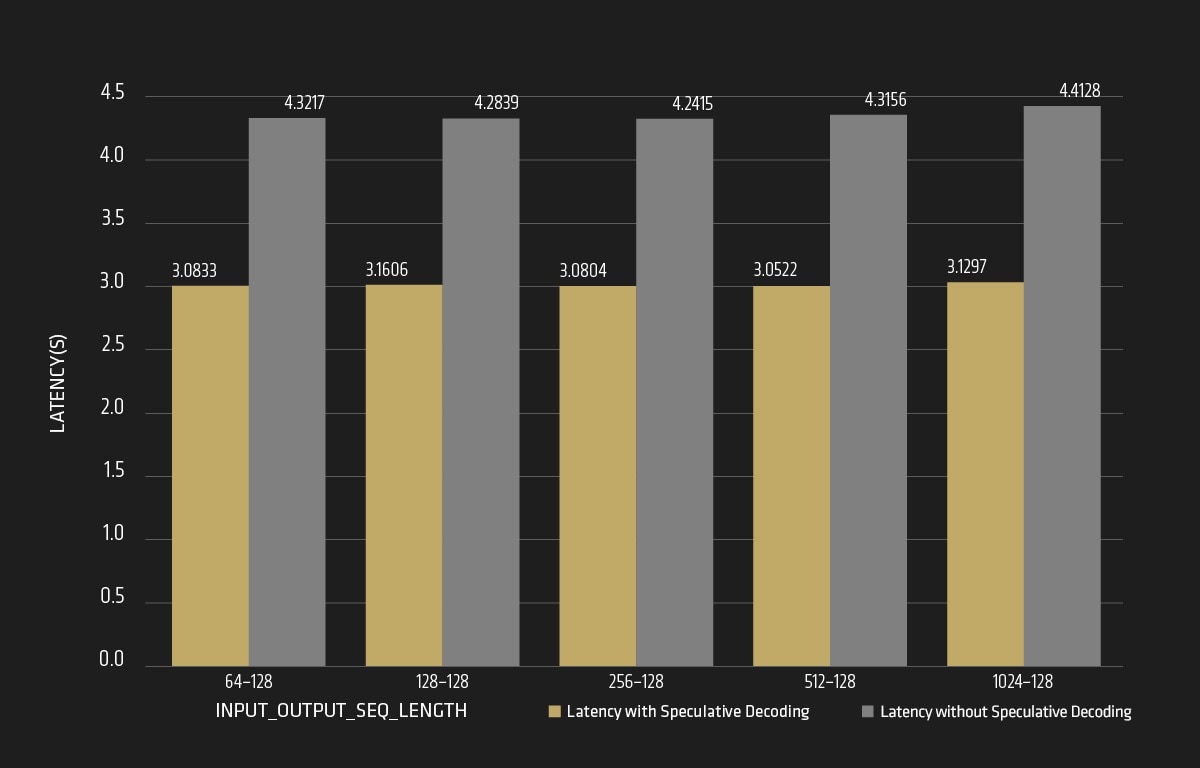
As shown in Figure 8, for the amd/Llama-3.1-405B-Instruct-FP8-KV model, by using the amd/Llama-3.1-8B-Instruct-FP8-KV as its corresponding speculative model, the average request latency declines from 4 to 3 seconds, achieving about 1.3X speedup when speculative decoding is enabled.
Conclusion
Speculative decoding is a powerful technique that enhances the efficiency and quality of text generation by predicting multiple potential continuations for a given input, resulting in faster and more coherent outputs. For users interested in trying it out, a detailed step-by-step guide will be provided in part 4 of this blog series on how to run these features on AMD Instinct™ MI300X accelerators. We will walk you through each process, ensuring your replication of the optimization steps effectively. Furthermore, the final AMD vLLM blog will include a roadmap detailing the upcoming support for vLLM on AMD platforms, outlining new features and enhancements that can be expected in the near future.
Footnotes
MI300-072:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model average request latency when speculative decoding enabled or not enabled. The data type is FP8 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input_output_sequence_length 64-128 | latency with speculative decoding 2.06 | latency without speculative decoding 3.33 | ratio – 1.62X;
Input_output_sequence_length 128-128 | latency with speculative decoding 2.02 | latency without speculative decoding 3.33 | ratio – 1.65X;
Input_output_sequence_length 256-128 | latency with speculative decoding 2.08 | latency without speculative decoding 3.35 | ratio – 1.61X;
Input_output_sequence_length 512-128 | latency with speculative decoding 2.08 | latency without speculative decoding 3.39 | ratio – 1.62X;
Input_output_sequence_length 1024-128 | latency with speculative decoding 2.18 | latency without speculative decoding 3.48 | ratio – 1.6X.
Performance may vary based on different hardware configurations, software versions and optimization.
MI300-073:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-405B model average request latency when speculative decoding enabled or not enabled. The data type is FP8 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input_output_sequence_length 64-128 | latency with speculative decoding 3.0833 | latency without speculative decoding 4.3217 | ratio – 1.40X;
Input_output_sequence_length 128-128 | latency with speculative decoding 3.1606 | latency without speculative decoding 4.2839 | ratio – 1.36X;
Input_output_sequence_length 256-128 | latency with speculative decoding 3.0804 | latency without speculative decoding 4.2415 | ratio – 1.38X;
Input_output_sequence_length 512-128 | latency with speculative decoding 3.0522 | latency without speculative decoding 4.3156 | ratio – 1.41X;
Input_output_sequence_length 1024-128 | latency with speculative decoding 3.1297 | latency without speculative decoding 4.4128 | ratio – 1.42X.
Performance may vary based on different hardware configurations, software versions and optimization.
Footnotes
MI300-072:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-70B model average request latency when speculative decoding enabled or not enabled. The data type is FP8 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input_output_sequence_length 64-128 | latency with speculative decoding 2.06 | latency without speculative decoding 3.33 | ratio – 1.62X;
Input_output_sequence_length 128-128 | latency with speculative decoding 2.02 | latency without speculative decoding 3.33 | ratio – 1.65X;
Input_output_sequence_length 256-128 | latency with speculative decoding 2.08 | latency without speculative decoding 3.35 | ratio – 1.61X;
Input_output_sequence_length 512-128 | latency with speculative decoding 2.08 | latency without speculative decoding 3.39 | ratio – 1.62X;
Input_output_sequence_length 1024-128 | latency with speculative decoding 2.18 | latency without speculative decoding 3.48 | ratio – 1.6X.
Performance may vary based on different hardware configurations, software versions and optimization.
MI300-073:
Testing conducted internally by AMD as of October 30th, 2024, on AMD Instinct MI300X accelerator, measuring Llama3.1-405B model average request latency when speculative decoding enabled or not enabled. The data type is FP8 and 10 iterations were tested.
Configuration:
AMD EPYC™ 9654 96-Core Processor, Ubuntu20.04, AMD Instinct™ MI300X (192GB HBM3, 750W) GPUs, single node with 8x MI300X
Python 3.9_and vLLM_0.6.4.
ROCm™ 6.2
Input_output_sequence_length 64-128 | latency with speculative decoding 3.0833 | latency without speculative decoding 4.3217 | ratio – 1.40X;
Input_output_sequence_length 128-128 | latency with speculative decoding 3.1606 | latency without speculative decoding 4.2839 | ratio – 1.36X;
Input_output_sequence_length 256-128 | latency with speculative decoding 3.0804 | latency without speculative decoding 4.2415 | ratio – 1.38X;
Input_output_sequence_length 512-128 | latency with speculative decoding 3.0522 | latency without speculative decoding 4.3156 | ratio – 1.41X;
Input_output_sequence_length 1024-128 | latency with speculative decoding 3.1297 | latency without speculative decoding 4.4128 | ratio – 1.42X.
Performance may vary based on different hardware configurations, software versions and optimization.
Overview
This is part 4 of a four-part AMD vLLM blog series. We previously introduced the advanced vLLM techniques of prefix caching, chunked prefill, and speculative decoding, and have showcased their significant improvements on large model inference performance on AMD GPUs. This final blog will transition from theory to practice. Below you will find a comprehensive hands-on guide for those eager to reproduce these optimizations and witness firsthand the enhancements they offer. This guide will provide step-by-step instructions designed to ensure you can effectively implement these techniques on the AMD Instinct™ MI300X accelerator.
Implementation Guide
Prerequisites
The implementation has been conducted on AMD Instinct MI300X accelerator, with ROCm™ 6.2, AMD EPYC 9654 96-Core CPU processor, and Ubuntu 22.04.4 LTS.
To get the optimized performance, it is recommended to disable automatic NUMA balancing. Failure to do so may result in the GPU being unresponsive until the periodic balancing is finalized. For further details, please refer to the AMD Instinct MI300X system optimization guide.
# disable automatic NUMA balancing
sh -c 'echo 0 > /proc/sys/kernel/numa_balancing'
# check if NUMA balancing is disabled (returns 0 if disabled)
cat /proc/sys/kernel/numa_balancing
0
sudo rocm-smi --setperfdeterminism 1900
For MI300X (gfx942) users, to achieve optimal performance, please refer to MI300x tuning guide for performance optimization and tuning tips on system and workflow level.
The NCCL_MIN_NCHANNELS argument controls the minimum number of communication channels that NCCL will use for collective operations. The default value for this is generally 1, but it can be increased for scaling out communication across multiple GPUs, especially when using multiple nodes or large-scale setups.
export NCCL_MIN_NCHANNELS=112
Step 1: Pull the Docker image from Docker Hub.
docker pull rocm/vllm:rocm6.2_mi300_ubuntu20.04_py3.9_vllm_0.6.4
Inside the docker, you are ready to run the following commands. Note that for other supported GPUs beyond AMD Instinct MI300X, vLLM can be installed using the instructions at docs.vllm.ai.
export VLLM_USE_TRITON_FLASH_ATTN=0
To use CK flash-attention or PyTorch naive attention, please use this flag to turn off triton flash attention.
Step 2: Set up the Path
cd /app/vllm/benchmarks
Please modify the path as your own path, Eg,
MODEL PATH
/workspace/home/models/Meta-Llama-3.1-70B-Instruct
DATASET PATH
/app/vllm/benchmarks/dataset/ShareGPT_V3_unfiltered_cleaned_split.json
Prefix Caching
CLI command
python benchmark_prefix_caching.py --model /workspace/home/models/Meta-Llama-3.1-70B-Instruct --dataset-path /app/vllm/benchmarks/dataset/ShareGPT_V3_unfiltered_cleaned_split.json --tensor-parallel-size 4 --output-len 256 --enable-prefix-caching --num-prompts 500 --repeat-count 10 --input-length-range "128:256" --seed 10
Sample Output
Testing filtered datasets
------warm up------
Processed prompts: 100%|████████████████████████| 5000/5000 [06:37<00:00, 12.58it/s, est. speed input: 2399.98 toks/s, output: 2136.81 toks/s] cost time 399.1660280227661
------start generating------
Processed prompts: 100%|████████████████████████| 5000/5000 [06:21<00:00, 13.11it/s, est. speed input: 2499.31 toks/s, output: 2224.97 toks/s] cost time 383.3819646835327
Chunked Prefill
CLI command for Throughput measurement
python benchmark_throughput.py --model /workspace/home/models/Llama-3.1-70B-Instruct --tokenizer /workspace/home/models/Llama-3.1-70B-Instruct --backend vllm --dataset /app/vllm/benchmarks/dataset/ShareGPT_V3_unfiltered_cleaned_split.json --tensor-parallel-size 4 --enable-chunked-prefill --max-model-len 128000 --max-num-batched-tokens 65536
Sample Output
Throughput: 9.33 requests/s, 3857.53 tokens/s
CLI command for Latency measurement
python benchmark_latency.py --model /workspace/home/models/Llama-3.1-70B-Instruct --tokenizer /workspace/home/models/Llama-3.1-70B-Instruct --tensor-parallel-size 4 --input-len 16384 --output-len 256 --batch-size 128 --enable-chunked-prefill --num-iters-warmup 3 --num-iters 3
Sample Output
Avg latency: 1456.6092147114978 seconds
10% percentile latency: 1456.2794379214756 seconds
25% percentile latency: 1456.5207454319752 seconds
50% percentile latency: 1456.6131397054996 seconds
75% percentile latency: 1456.7309634970297 seconds
90% percentile latency: 1456.935066507518 seconds
99% percentile latency: 1457.110477680646 seconds
Speculative Decoding
CLI command
python benchmark_latency.py --model /workspace/models/Llama-3.1-70B-Instruct-FP8-KV --max-model-len 26720 --batch-size 1 --use-v2-block-manager --input-len 8192 --output-len 128 --speculative-model /workspace/models/Llama-3.1-8B-Instruct-FP8-KV --num-speculative-tokens 5
Sample Output
Profiling iterations: 100%|████████████████████████████████████████| 30/30 [03:05<00:00, 6.19s/it]
Avg latency: 6.1900297301336344 seconds
10% percentile latency: 5.713031815201975 seconds
25% percentile latency: 5.857956004001608 seconds
50% percentile latency: 6.123988274484873 seconds
75% percentile latency: 6.298471801499545 seconds
90% percentile latency: 6.877943714798312 seconds
99% percentile latency: 7.624673274156521 seconds
Additional Optimizations
Optimizing CPU Overheads in LLM Serving
In the realm of LLMs, the CPU plays a crucial role in ensuring smooth and efficient operations. In addition to above hands-on guide, this blog also examines the key tasks that are managed by the CPUs and explain why optimizing these tasks is essential for improved performance.
Key Tasks of CPU in LLM Serving
The CPU undertakes several critical responsibilities to maintain the efficiency and responsiveness of LLM services. There are 4 key tasks for the CPU in LLM Serving:
- Handling HTTP Requests and Streaming Output Tokens: The CPU is responsible for managing incoming HTTP requests, which are essential for interacting with the LLM. Additionally, it streams the output tokens generated by the model, ensuring that responses are delivered promptly.
- Scheduling Requests at Every Step: Efficient scheduling of requests is vital to maintain seamless operation flow. The CPU schedules these requests at each step, coordinating the tasks to ensure that the model runs smoothly.
- Preparing Input Tensors and Gathering Output Tensors: Prior to the data processing, the CPU prepares the input tensors. After processing, it gathers the output tensors, which are subsequently transformed into meaningful responses.
- Converting Output Tokens into Strings: The final step involves converting the output tokens generated by the model into strings that can be understood and used by end-users.
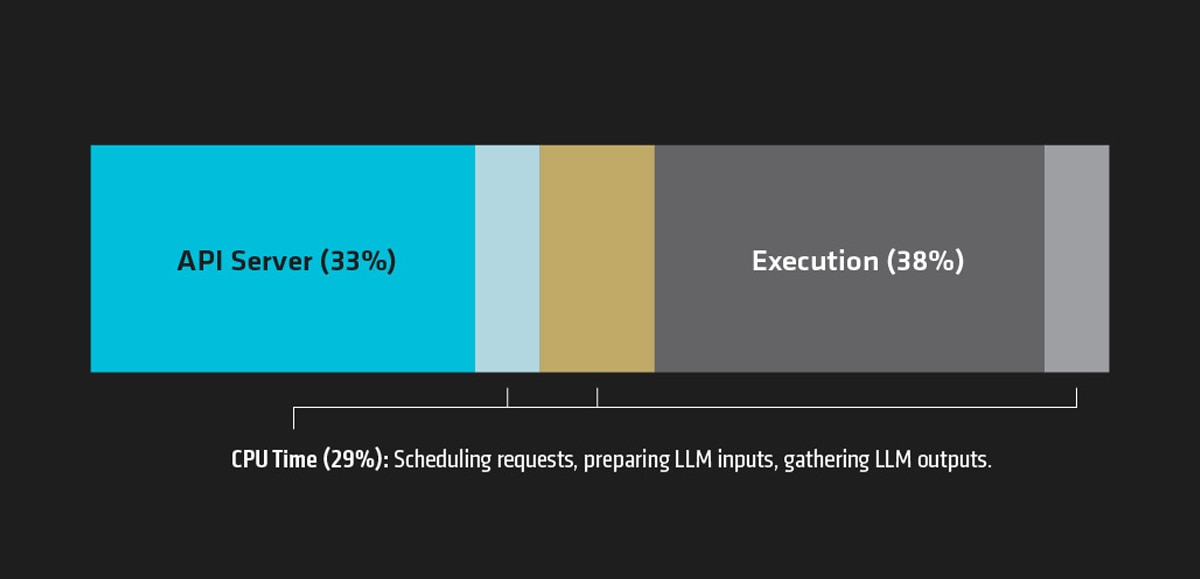
To illustrate the impact of CPU overheads, consider the example of serving the Llama-3-8B model (Figure 9). In this scenario, the GPU experienced idleness for up to 60% of the time. This idleness was primarily due to the time spent by the CPU on scheduling requests, preparing inputs, and gathering outputs. This example highlights the importance of optimizing CPU tasks to minimize idle time and improve overall efficiency.
By identifying and addressing these CPU overheads, it is possible to enhance the performance of LLM serving, ensuring faster and more efficient processing of requests. This not only improves the user experience but also maximizes the utilization of available resources.
Recommended Strategies to Minimize CPU Overheads
To address the inefficiencies caused by CPU overheads and enhance the performance of large language model serving, consider the following strategies to optimize CPU overheads:
- Separating API server and engine processes using multiprocessing and ZeroMQ to remove API server overheads from the critical path, thereby achieving great performance under high QPS (queries per second).
- Implementing multi-step scheduling to schedule multiple steps ahead, thereby amortizing the cost of scheduling and input preparation.
- Adopting asynchronous output processing to overlap de-tokenization and stop string matching with model execution, which adds one extra step per request but significantly increases GPU utilization outweighs the cost.
Scalable System Architecture
To achieve a more scalable system architecture, several key strategies are being implemented.
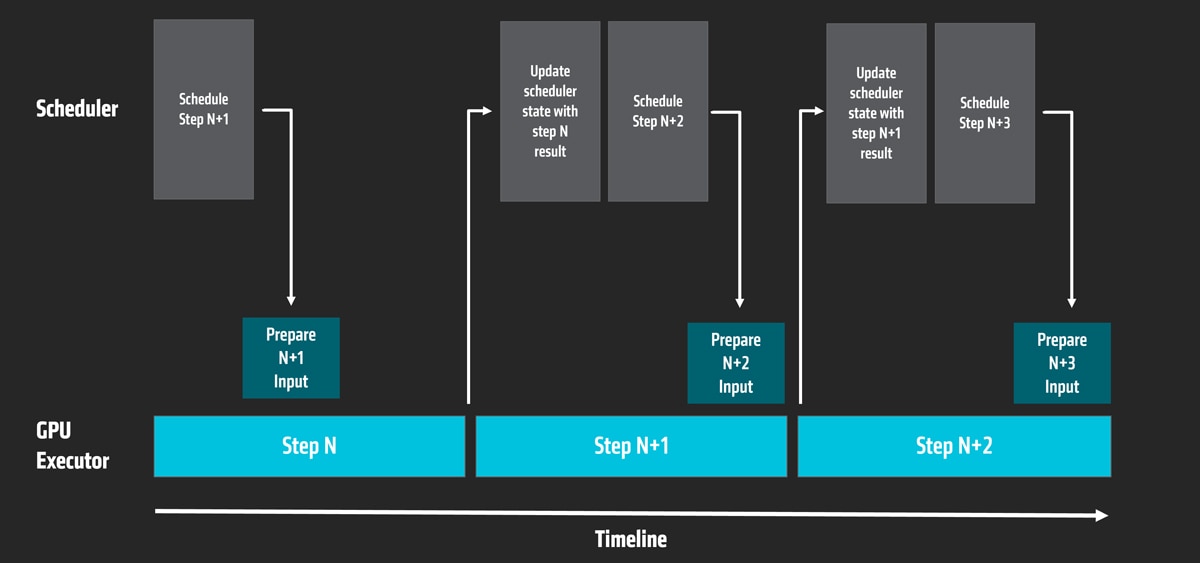
Asynchronous scheduling is being generalized to enhance both output processing and multi-step scheduling, while incremental input preparation aims to reuse input and output tensors from previous steps, thereby improving efficiency.
In the context of vLLM and torch.compile, the optimization process involves four steps: first, optimizing certain operators using torch.compile; second, capturing the full model with TorchDynamo; third, compiling the full model with TorchInductor; and finally, adding custom optimizations on top of torch.compile.
Additionally, the development of multi-modal models is being advanced with contributions from model vendors, introducing new modalities such as audio with models like Ultravox. These models also feature support for dynamic image sizes, multi-image interfaces, and image embeddings as input, along with new optimizations like optimized kernels and tensor parallelism support for vision encoders.
vLLM Roadmap
The future vLLM roadmap will mainly focus on re-architecture, with deeper integration into the PyTorch ecosystem using tools like torch.compile and Triton to optimize performance and compatibility. Enhancements will include better support for Vision-Language Models (VLMs) and the introduction of new modalities such as speech and video. Additionally, efficient support for long context scenarios is being developed, including disaggregating serving and key-value (KV) cache transfer processes, as well as implementing sequence parallelism to ensure smoother and faster processing.
Conclusion
The strategic partnership between AMD and open-source innovators like vLLM aims to utilize AMD Instinct GPUs, ROCm software, and features like prefix caching, chunked prefill, and speculative decoding for optimal performance. By integrating advanced memory optimization techniques, efficient execution algorithms, and further optimizations on the vLLM roadmap with an emphasis on minimizing CPU overhead in LLM serving, this partnership intends to improve the capability and efficiency of large model inference, making it more accessible and effective for real-world applications. Stay tuned for more updates as we continue to innovate and enhance vLLM features on AMD. For more inquiries, contact us at amd_ai_mkt@amd.com.
