Powered by DeepSeek: Play Minecraft with AMD GPUs and AI PC
Mar 18, 2025
Introduction
Minecraft is an endlessly sandbox game set in a blocky, pixelated world, that allows players to build, explore, and survive in a dynamic environment. Players can craft tools, construct magnificent structures, dig deep into mysterious caves, and battle against creatures like zombies and creepers. Minecraft's open-ended environment presents diverse challenges that require complex decision-making, strategic planning, and creative problem-solving skills critical for real-world AI applications. Rooted in our admiration for the game, AMD built: MoEA: A Mixture-of-Experts Agent for Open-World Minecraft with Multimodal Expert Memory, an LLM-empowered agent that can complete various tasks in Minecraft automatically. It enhances adaptability and generalization by integrating online RL training with a multi-expert memory module. Specifically, MoEA overcomes the limitations of training data by dynamically triggering the online training of low-level controllers and storing them in a multi-expert memory. When faced with a new task, MoEA uses multi-modal information to identify and activate the most relevant expert, achieving robust generalization across diverse scenarios.

Method
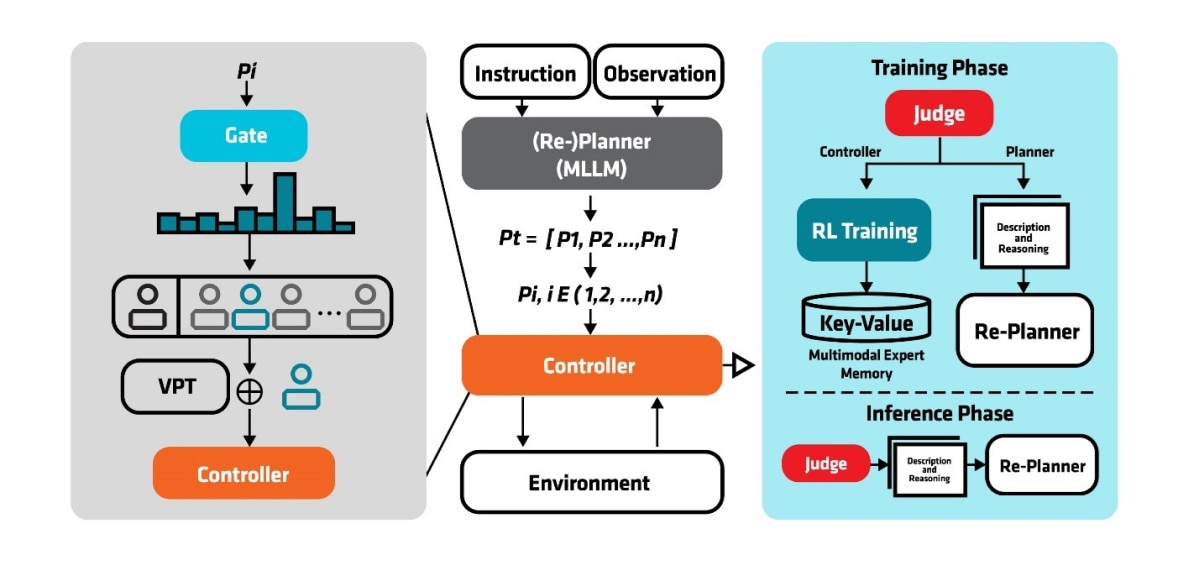
AMD framework consists of four main components as shown in Figure 1: (1) the high-level planner, responsible for generating optimal plans; (2) the low-level controller, which interacts with the environment; (3) the judge, which evaluates the causes of failure; and (4) the multimodal expert memory, which stores and retrieves expert policy to improve the agent’s ability to execute tasks more effectively.
In inference phase, when the agent receives an instruction, such as “build a house”, the LLM-powered high-level planner first generates an initial task plan. Then the controller executes subtasks in the task plan sequentially. Before each execution of a subtask, the gating network dynamically selects the most relevant expert from the Multimodal Expert Memory.
In training phase, a controller tries to complete the received subtask from the high-level planner. Successful completion of the subtask triggers sequential progression to the next subtask. But if the execution fails (e.g. upon reaching maximum allowed steps), the system invokes the judge module for failure analysis. The judge module performs multisource analysis integrating environmental states, inventory state, and previous plan. Through contextual reasoning, it categorizes failures into planning errors and policy limitations. If the failure is caused by planning errors, the planner will regenerate an improved task plan with feedback. Otherwise, RL training will be triggered to train a new controller for the specific task and environment. The optimized policy will then be stored in the multi-modal expert memory.
Multimodal Expert Memory
Unlike previous approaches that primarily store examples of successful or failed trajectories to guide the planner in decision-making, our multimodal expert memory employs a key-value structure, where key combines task description, package info and environment states. Value stores task-specific experts in terms of policy weights.
A Gate Network retrieves the most relevant expert from the multimodal expert memory through a two-stage matching process. In stage one, we embed the task and environment with MineClip and find the top N expert candidates that best match according to the cosine similarity. In stage two, we compare the package presence and find the best aligned expert.
RL Training
Our controller is based on STEVE-11, which has been fine-tuned for instruction-following using the foundation model VPT. As shown in Figure 2, the backbone of this controller is built upon the Transformer-XL architecture, featuring both an action head and a value head. The input consists of two components: (1) the current subgoal and (2) the environmental observation, which are used to predict the next action. In the design, only the two heads are trained, with the backbone frozen.
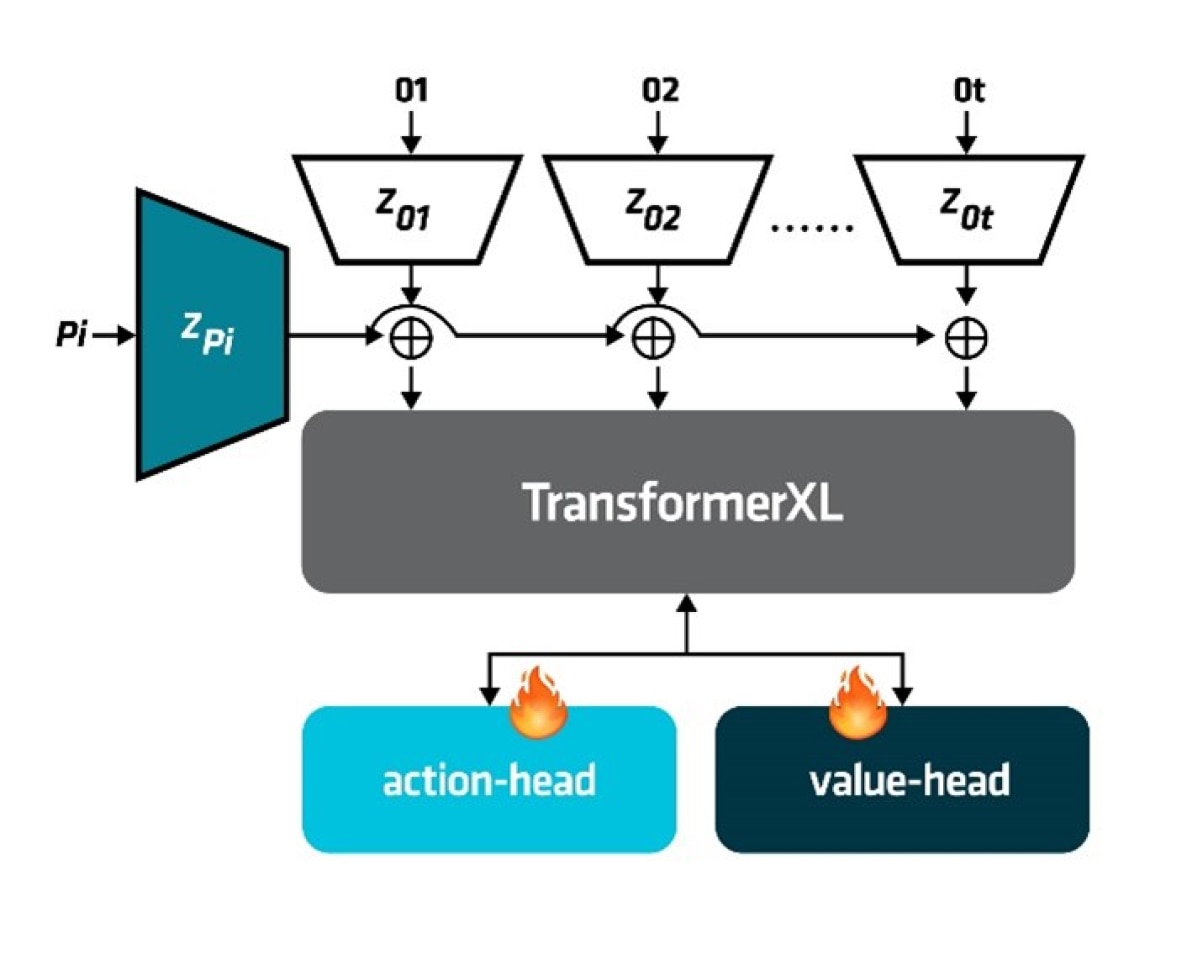
We use PPO (Proximal Policy Optimization) for optimization. The design of sparse reward functions, employing a simple ‘task completion yields reward’ scheme, provides clear and direct feedback to the agent. In this way, the agent can effectively learn and optimize its policy in sparse reward environments, ultimately achieving efficient task completion.
Experiments
The experiments utilize the Minecraft environment established in JARVIS-12, which provides human-aligned interaction protocols through structured API access and comprehensive task definitions.
AMD did benchmark MoEA against state-of-the-art LLM-based agents for multi-task instruction execution, including InstructGPT 3, which is a base LLM with chain-of-thought prompting; ReAct4, which is a Reasoning-acting framework with environment feedback; DEPS5, which is a dynamic task decomposition with self-correction; JARVIS-2, which is the current SOTA in Minecraft agent benchmarks.
Metrics. Agents are evaluated in standard Minecraft survival mode, starting with empty inventories and randomized spawn positions to capture real-world environmental variability. Task success is defined as obtaining specified target items within task-specific time limits. To ensure statistical robustness, multiple independent trials are conducted per task with controlled seed variations for environment generation. Performance is measured using the Success Rate, calculated as the ratio of successful trials to total trials.
Is AMD MoEA better than SOTA Method?
Results in Table 1 show that AMD MoEA framework outperforms state-of-the-art methods, achieving success rates from 36.76% to 100%. This is due to MoEA’s ability to address the critical bottleneck in controller execution. For example, in the food task group, MoEA achieves 54.48% success for cooking cooked chicken, a 52.95% improvement over Jarvis-1. This highlights MoEA’s strength in overcoming controller limitations, especially in multi-step tasks requiring precise tool interactions (e.g., cooking). The improvement is driven by MoEA’s dynamic online training and multi-expert memory, which bridge the generalization gap of traditional single-controller systems.
As task complexity increases from wood collection to food preparation, MoEA maintains stable performance, achieving 95.65% success in furnace-related tasks vs. 54.48% in cooking cooked chicken. In contrast, baseline methods like GPT and ReAct fail in more complex tasks (0–6.67% success in iron/food). This scalability is due to MoEA’s dynamic controller training, which adapts quickly by training and storing specialized experts, ensuring reliable performance with limited prior data.
Within task groups, MoEA activates contextually relevant controllers. For instance, in the iron group, the bucket task sees the largest gain (+12.49%) over iron pickaxe (+8.69%) due to dynamic tool-switching, a challenge where MoEA’s multi-expert memory excels in retrieving water collection skills. Similarly, MoEA achieves a 53.12% improvement in boat tasks, compared to just 9.23% in chest tasks, demonstrating its adaptability in tasks requiring precise spatial actions, like plank assembly.
Group |
Tast |
GPT |
ReAct |
DESP |
JARVIS-1 |
MoEA |
REL. |
Wood |
Chest |
26.67 |
45.00 |
75.00 |
91.55 |
100.0 |
9.23%↑ |
Oak_fence |
19.94 |
51.00 |
78.30 |
80.00 |
96.67 |
20.84%↑ |
|
Boat |
6.67 |
36.67 |
36.67 |
60.47 |
92.59 |
53.12%↑ |
|
Stone |
Furnace |
20.00 |
20.00 |
75.00 |
94.20 |
95.65 |
1.54%↑ |
Smoker |
20.21 |
38.15 |
70.00 |
78.67 |
80.00 |
1.69%↑ |
|
Iron |
Iron_Pickaxe |
0.00 |
0.00 |
20.00 |
33.82 |
36.76 |
8.69%↑ |
Bucket |
3.33 |
6.67 |
20.00 |
38.10 |
42.86 |
12.49%↑ |
|
Food |
Cooked_Chicken |
0.00 |
0.00 |
16.67 |
35.62 |
54.48 |
52.95%↑ |
Table 1: Main results comparing the performance (%) of different methods across task groups. REL.: Relative improvement of MoEA over Jarvis-1. Metrics show task success rates in a standardized Minecraft environment. Bold font indicates the best result, and the ↑symbol denotes performance improvement. MoEA achieves significant gains across all tasks, with the largest relative improvement (53.12%) in the “BOAT” task.
Is AMD Task-specific Expert Directly Useful?
To evaluate the efficacy of standalone experts, we test four basic tasks where experts operate independently (seeds, dirt, flower, log). As shown in the Table 2, significant improvements are observed in three tasks: seeds (+82.09%), dirt (+26.23%), and flower (+350.0%), demonstrating the experts’ effectiveness in goal execution. Notably, experts not only increase mean success rates but also expand the maximum achievable quantities (e.g., flower improves from 1 to 3 items per trial), indicating enhanced efficiency. However, log shows a slight decline (-1.69%) as agents have already reached near optimal performance under step limits (11.8 vs. 11.6 items), leaving no room for further improvement. This confirms that task-specific experts enhance execution quality when not constrained by environmental limitations.
Task |
Before |
After |
REL. |
Seeds |
4.30(7) |
7.83(11) |
82.09%↑ |
Dirt |
12.20(15) |
15.40(17) |
26.23%↑ |
Flower |
0.40(1) |
1.8(3) |
350.0%↑ |
Log |
11.8(13) |
11.6(13) |
-1.69%↓ |
Table 2: Performance comparison (mean) of task-specific experts on four basic tasks with no planner involvement. REL: Relative improvement between baseline (Before) and RL-enabled expert (After). The values in parentheses represent the maximum achievable quantities in the tests.
Now DeepSeek Models are Supported Locally
MoEA framework is not limited to any specific LLM model. Recently, we successfully deployed the distilled Deepseek-R1 model in the MoEA framework both on an AMD Instinct™ MI250 GPU and AMD powered AI PC. Below is a demo video of DeepSeek-based MoEA completing the crafting smithing table task. Crafting smithing table is a very complex task. According to the Minecraft recipe, to craft a smithing table needs Iron Ingots and planks. To obtain Iron Ingots, player needs to smelt Iron Ore with fuel in a furnace. To mine iron ore, player first needs to craft a stone pickaxe, which needs stone-tier block and stick to craft. The task is continuously broken down into many subtasks in this way. The agent starts with only an iron axe. It decomposes the task itself and autonomously decides the next step based on the current environment until the task of crafting a smithing table is completed.
Conclusion
MoEA is an effective and versatile agentic framework, that can make complex decisions and keep evolving itself. With self-triggered RL training, it overcomes the limitations of training data. Multimodal Expert Memory make it a very light-weight framework. With the support of AMD advanced hardware, players can easily deploy the framework on their laptop. As next steps, AMD aims to make MoEA a more general Agent, which can run on your own AI PC efficiently, other than just playing Minecraft.
Footnotes
- Lifshitz, S., Paster, K., Chan, H., Ba, J., and McIlraith, S. Steve-1: A generative model for text-to-behavior in minecraft. Advances in Neural Information Processing Systems, 36, 2024.
- Wang, Z., Cai, S., Liu, A., Jin, Y., Hou, J., Zhang, B., Lin, H., He, Z., Zheng, Z., Yang, Y., et al. Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024b.
- Huang, W., Abbeel, P., Pathak, D., and Mordatch, I. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International conference on machine learning, pp. 9118–9147. PMLR, 2022a.
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Wang, Z., Cai, S., Chen, G., Liu, A., Ma, X., and Liang, Y. Describe, explain, plan and select: Interactive planning with large language models enables open-world multitask agents. arXiv preprint arXiv:2302.01560, 2023.
Footnotes
- Lifshitz, S., Paster, K., Chan, H., Ba, J., and McIlraith, S. Steve-1: A generative model for text-to-behavior in minecraft. Advances in Neural Information Processing Systems, 36, 2024.
- Wang, Z., Cai, S., Liu, A., Jin, Y., Hou, J., Zhang, B., Lin, H., He, Z., Zheng, Z., Yang, Y., et al. Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024b.
- Huang, W., Abbeel, P., Pathak, D., and Mordatch, I. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International conference on machine learning, pp. 9118–9147. PMLR, 2022a.
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Wang, Z., Cai, S., Chen, G., Liu, A., Ma, X., and Liang, Y. Describe, explain, plan and select: Interactive planning with large language models enables open-world multitask agents. arXiv preprint arXiv:2302.01560, 2023.
