Model Pipelining on NPU and GPU using Ryzen AI Software
Aug 02, 2024
Introduction
In the world of Deep Learning and Generative AI, efficient utilization of computational resources is vital for achieving optimal performance. In this blog, we will explore the power of using a Ryzen™ AI-enabled processor, equipped with a CPU, Neural Processing Unit (NPU), and integrated GPU (iGPU), to build a high-performance application through strategic pipelining of models. By distributing and off-loading distinct models onto the NPU and iGPU based on their computational requirements and hardware support, we can maximize the potential of the processor. We will delve into the implementation of two Convolutional Neural Network (CNN) models on the NPU, alongside one generative model on the iGPU. We demonstrate enhanced inference performance achieved when using ONNX Runtime - Vitis™ AI Execution Provider (EP) and DirectML EP on the respective hardware. Through this approach, we aim to optimize the application's performance while maximizing the utilization of the available accelerator resources.

Strategic model-offloading for optimal performance
An end-to-end application often deploys multiple models running in a pipeline on an AI PC. The choice of hardware may depend on the model characteristics, performance, power requirements, and the trade-offs in offloading models to the NPU or integrated GPU. An integrated GPU can efficiently handle very large iterative models that might become bottlenecks when running on a CPU, offering significant performance advantages in terms of throughput or latency. While an NPU also improves performance, it has the added benefit of running models with lower power consumption. Therefore, long-running models often benefit from running on the NPU to achieve significant power savings.
Ryzen AI Software stack

Vitis™ AI and Direct ML Execution Provider
ONNX Runtime is a high-performance, cross-platform deployment framework that aims to accelerate machine learning model inferencing and computation. One of the key features of ONNX Runtime is its extensibility that allows the development of custom Execution Providers (EPs) for various hardware accelerators. This flexibility enables developers to harness the power of different processing units, adapting to specific requirements and optimizing the performance of AI applications.
Two such custom Execution Providers we will utilize are the Vitis AI EP and the DirectML EP. The Vitis AI EP is designed to facilitate deployment on the Ryzen AI NPU. It intelligently determines what portions of the model should run on the NPU, optimizing workloads to ensure optimal performance with low power consumption. On the other hand, the DirectML EP enables the deployment of AI models on GPUs, specifically utilizing the DirectML library included with the Microsoft AI Platform. The DirectML EP can be used to deploy models on Ryzen AI’s integrated GPU.
AMD Vitis AI Quantizer
Before offloading the model through the Vitis AI Execution Provider, it needs to be quantized. AMD Vitis AI Quantizer offers various quantization methods, including Post-Training Quantization (PTQ) and Quantization Aware Training (QAT), compatible with popular frameworks like ONNX and PyTorch. In this use case, we have obtained pre-quantized models from the Ryzen AI Model Zoo (more about Ryzen AI Model Zoo below). However, if you intend to use your own model or a fine-tuned model not available in the Ryzen AI Model Zoo, you will need to quantize the model using an appropriate method.
Microsoft Olive
Microsoft Olive is a tool designed to streamline and enhance the performance of AI models. It provides a seamless way to optimize models for various hardware targets, enabling efficient execution and next-level inference speeds. By leveraging advanced optimization techniques, Olive reduces the complexity and overhead associated with deploying models, making it easier for developers to achieve high-performance results on a range of devices, including those utilizing DirectML Execution Provider on integrated GPUs (iGPU). With Olive, optimizing models for real-world applications becomes a more straightforward and effective process. For this use case, we have used Olive to optimize a stable-diffusion image-to-image model.
Sample model pipeline
We will look at an application that off-loads different components in an application to the NPU and iGPU.
Models
For our application, we will consider 3 tasks:
- Object Detection (OD), using Yolov8
- Super Resolution (SR), using RCAN
- Style Transfer (ST), using Stable Diffusion (Img2Img)
We will use these models to establish 3 concepts, mainly:
- Concurrency on the NPU
- Concurrency on NPU + iGPU
- Deploying pipelined models on Ryzen AI
The source code for this application and corresponding instructions to run can be found here.
Pipeline
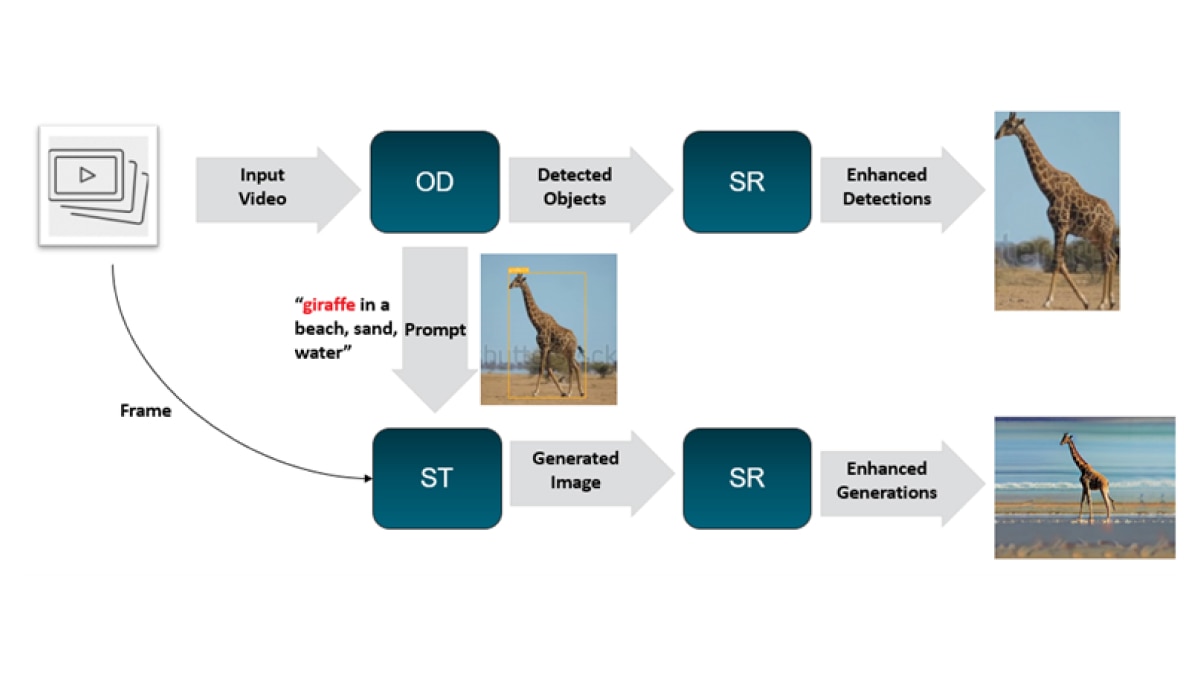
Our application consists of two main model pipelines
- Vision Pipeline: A common video analytics task is object detection, followed by other tasks such as classification, resolution enhancement, etc. In this example, we have demonstrated object detection followed by a super resolution task.
- Diffusion-Vision Pipeline: In parallel, we have a Stable Diffusion Img2Img model that takes in an input frame, and output from the object detector to perform style transfer. The Stable Diffusion model will run on the iGPU, given its computational requirements. The generated image will then go through RCAN for resolution enhancement.
Preparing models for deployment
Yolov8 and RCAN are obtained from Hugging Face Ryzen AI Model Zoo, which offers a collection of quantized ONNX models that are specifically optimized for deployment on Ryzen AI NPUs. These are pre-trained, quantized models that enable fast inferencing and seamless deployment on the Ryzen AI NPU. This can help developers streamline their deployment process, save valuable development time, and ensure optimal performance on Ryzen AI-enabled processors. Utilizing this resource in conjunction with ONNX Runtime, Vitis AI EP, and DirectML EP, developers can build powerful AI applications that effectively distribute workloads across the NPU and iGPU.
The Stable Diffusion Img2Img model is available in the Diffusers library. Further optimizations to the model are optional. We will use Olive to optimize the components of Stable Diffusion Img2Img. Each of the PyTorch models in Stable Diffusion is converted to ONNX, and then run through OrtTransformersOptimization pass by Olive. To perform olive optimization, use the following command:
>>cd stable_diffusion
stable_diffusion py --provider dml –optimize
Running the Application
Running the application requires Ryzen AI laptop installed with Ryzen AI 1.2 software. Please ensure to follow the installation instructions from here .
Let us review the runtime code that uses multiple ONNX Runtime sessions to run these models on different hardware.
from diffusers import OnnxStableDiffusionImg2ImgPipeline
provider_map = {
"dml": ('DmlExecutionProvider', {
'device_id': 0,
}),
}
assert provider in provider_map, f"Unsupported provider: {provider}"
return OnnxStableDiffusionImg2ImgPipeline.from_pretrained(
model_dir, provider=provider_map[provider], sess_options=sess_options
)
The code snippet above shows the use of an ONNX Runtime session with the DirectML execution provider for running a Stable Diffusion image-to-image model. The diffusers library provides OnnxStableDiffusionImg2ImgPipeline that can be used in conjunction with pretrained ONNX models for easy initialization of ONNX Runtime sessions.
if args.npu:
providers = ["VitisAIExecutionProvider"]
provider_options = [{"config_file": args.provider_config}]
else:
providers = ['CPUExecutionProvider']
provider_options = [{}]
onnx_model = onnxruntime.InferenceSession('yolov8m.onnx',
providers=providers,
provider_options=provider_options)
ort_session_rcan = onnxruntime.InferenceSession('RCAN_int8_NHWC.onnx',
providers=providers,
provider_options=provider_options)
Similarly, the code snippet above shows the creation of two ONNX Runtime sessions for Yolov8 and RCAN models. When the application is run with the NPU flag, the Vitis AI Execution Provider is used to run the models on the NPU.
The rest of the code implements the model pipeline by creating a thread pool to handle each of the tasks, and then executes these tasks in parallel to optimize performance.
To run the application, execute the following command
python pipeline.py <...>
For more details, review the README associated with this application.
Reviewing Performance numbers
In this section, we demonstrate the performance improvements achieved by deploying models on different hardware components.
Flow |
OD |
SR |
ST |
Total Inference Time |
1 |
CPU |
CPU |
CPU |
179.65 |
2 |
CPU |
CPU |
iGPU |
123.82 |
3 |
NPU |
NPU |
iGPU |
16.57 |
As shown in the table above, deploying the Stable Diffusion model on the GPU and subsequently the object detection and super-resolution models on the NPU, the total inference time is down from 179.65 seconds to 123.82 seconds, and finally to 16.57 seconds. This substantial reduction in latency highlights the benefits of strategic model deployment, which also leads to a significant improvement in throughput, measured in frames per second (fps).
The NPU also provides performance/watt benefits with low-power inference. In our sample application, we see around 10-15% reduction in median CPU power consumption by offloading the object detection and super resolution models onto the NPU. This reduction in power can be significant for real-world applications with long-running models on the NPU, resulting in extended battery life for the PCs.
Note that these results were obtained on a Phoenix PC, and performance may vary depending on the PC's capabilities and other factors. The absolute power consumption may also vary depending on other applications running on the PC.
Conclusion
In this blog, we've explored how the Ryzen AI-enabled processor can be used to deploy an AI application through effective use of its CPU, NPU, and integrated GPU. By assigning different AI models to the most suitable processing units—CNN models to the NPU and a generative models to the iGPU—we demonstrated a boost in performance as well as lower power utilization.
This strategy highlights the critical role of smart resource management in achieving optimal AI performance. Ryzen AI software empowers developers to fully exploit the capabilities of their hardware, enabling the creation of high-performance AI applications that are both powerful and efficient.
We encourage you to dive into Ryzen AI software and explore its potential. To get started and access additional resources, visit Ryzen AI SW Documentation and Examples, Tutorials, and Demo repository .
Embrace the future of AI PCs and discover how Ryzen AI can help you achieve new heights in performance and efficiency. For any questions, please send an email to amd_ai_mkt@amd.com.

Footnotes
DISCLAIMER: The information contained herein is for informational purposes only and is subject to change without notice. While every precaution has been taken in the preparation of this document, it may contain technical inaccuracies, omissions and typographical errors, and AMD is under no obligation to update or otherwise correct this information. Advanced Micro Devices, Inc. makes no representations or warranties with respect to the accuracy or completeness of the contents of this document, and assumes no liability of any kind, including the implied warranties of noninfringement, merchantability or fitness for particular purposes, with respect to the operation or use of AMD hardware, software or other products described herein. No license, including implied or arising by estoppel, to any intellectual property rights is granted by this document. Terms and limitations applicable to the purchase or use of AMD products are as set forth in a signed agreement between the parties or in AMD's Standard Terms and Conditions of Sale. GD-18u.
Ryzen™ AI is defined as the combination of a dedicated AI engine, AMD Radeon™ graphics engine, and Ryzen processor cores that enable AI capabilities. OEM and ISV enablement is required, and certain AI features may not yet be optimized for Ryzen AI processors. Ryzen AI is compatible with: (a) AMD Ryzen 7040 and 8040 Series processors except Ryzen 5 7540U, Ryzen 5 8540U, Ryzen 3 7440U, and Ryzen 3 8440U processors; (b) AMD Ryzen AI 300 Series processors, and (c) all AMD Ryzen 8000G Series desktop processors except the Ryzen 5 8500G/GE and Ryzen 3 8300G/GE. Please check with your system manufacturer for feature availability prior to purchase. GD-220c.
Links to third party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites and no endorsement is implied. GD-97.
© 2024 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Radeon, Ryzen, Vitis, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with the system manufacturer for specific features. No technology or product can be completely secure.
Footnotes
DISCLAIMER: The information contained herein is for informational purposes only and is subject to change without notice. While every precaution has been taken in the preparation of this document, it may contain technical inaccuracies, omissions and typographical errors, and AMD is under no obligation to update or otherwise correct this information. Advanced Micro Devices, Inc. makes no representations or warranties with respect to the accuracy or completeness of the contents of this document, and assumes no liability of any kind, including the implied warranties of noninfringement, merchantability or fitness for particular purposes, with respect to the operation or use of AMD hardware, software or other products described herein. No license, including implied or arising by estoppel, to any intellectual property rights is granted by this document. Terms and limitations applicable to the purchase or use of AMD products are as set forth in a signed agreement between the parties or in AMD's Standard Terms and Conditions of Sale. GD-18u.
Ryzen™ AI is defined as the combination of a dedicated AI engine, AMD Radeon™ graphics engine, and Ryzen processor cores that enable AI capabilities. OEM and ISV enablement is required, and certain AI features may not yet be optimized for Ryzen AI processors. Ryzen AI is compatible with: (a) AMD Ryzen 7040 and 8040 Series processors except Ryzen 5 7540U, Ryzen 5 8540U, Ryzen 3 7440U, and Ryzen 3 8440U processors; (b) AMD Ryzen AI 300 Series processors, and (c) all AMD Ryzen 8000G Series desktop processors except the Ryzen 5 8500G/GE and Ryzen 3 8300G/GE. Please check with your system manufacturer for feature availability prior to purchase. GD-220c.
Links to third party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites and no endorsement is implied. GD-97.
© 2024 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Radeon, Ryzen, Vitis, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with the system manufacturer for specific features. No technology or product can be completely secure.