Accelerating Generative LLMs Inference with Parallel Draft Models (PARD)
Apr 03, 2025
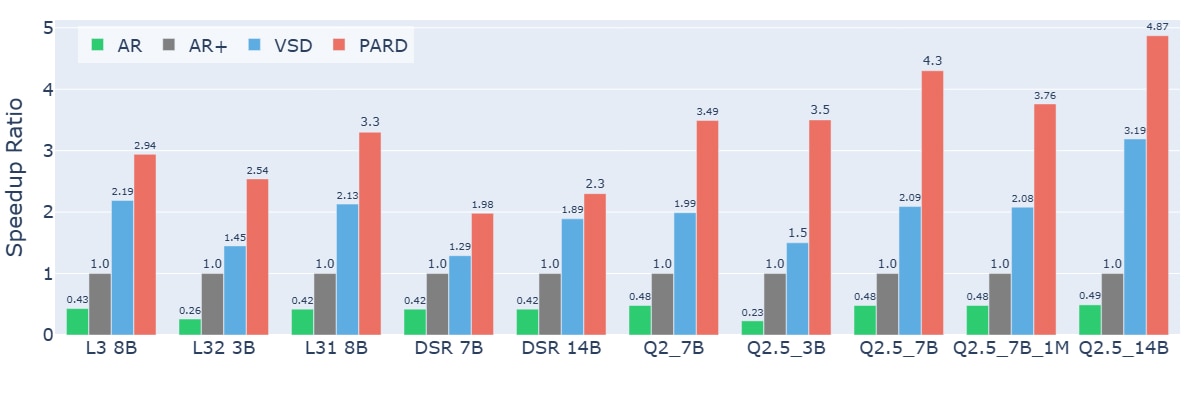
In recent years, generative AI has seen remarkable breakthroughs, from ChatGPT and Llama to o1, with continuous advancements in model capabilities. Models like DeepSeek-R1 have pushed inference performance to new heights, further enhancing AI’s reasoning abilities. At the same time, accelerating inference speed has become a key research focus. To address this, we introduce Parallel Draft (PARD), a highly adaptable method that leverages speculative decoding to significantly boost inference speed. With PARD, the Llama3 series achieve up to 3.3× speedup1 ,the DeepSeek series achieve up to 2.3× speedup2, and the Qwen series benefit from an impressive 4.87× speedup3 on 1x AMD Instinct MI250. This breakthrough presents fresh perspectives and innovative solutions for optimizing inference efficiency in generative AI models.
Speculative Decoding
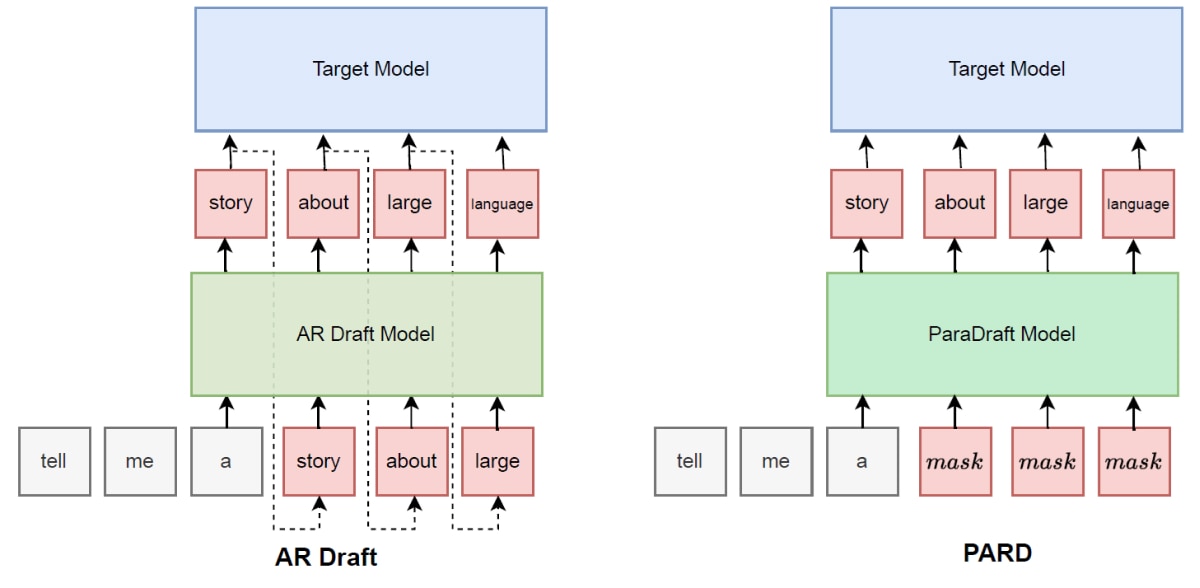
Large language models (LLMs) typically generate text in an autoregressive manner, producing one token at a time while conditioning on all previously generated tokens. Although this token-by-token process ensures coherence and logical consistency, it often becomes a bottleneck for inference speed. To address this, speculative decoding has emerged as an effective strategy. This technique utilizes a more computationally efficient draft model to pre-generate a sequence of candidate tokens, which is subsequently verified and refined by the main model. The result is a significant boost in throughput without compromising text quality a novel solution that overcomes the limitations of traditional token-by-token generation.
Parallel Draft Model
While speculative decoding already offers substantial efficiency gains, traditional approaches still require multiple forward passes through the draft model. Although this reduces the computational load on the target model, it introduces extra overhead. To further optimize inference, we propose the PARD method. Building on speculative decoding and incorporating a Parallel Mask Predict mechanism, this approach reduces the draft model’s forward passes to just once. Prior work, such as BiTA, ParallelSpec and PaSS, has employed Parallel Mask Predict to enhance inference efficiency. Expanding on these ideas, our new PARD method upgrades the conventional autoregressive (AR) draft model into a Parallel Draft Model through minimal fine-tuning, dramatically accelerating inference across models like Deepseek-R1-distilled, Llama3, and Qwen. PARD is a target-independent approach, allowing a single draft model to accelerate an entire family of target models, thereby reducing deployment costs.
PARD Inference
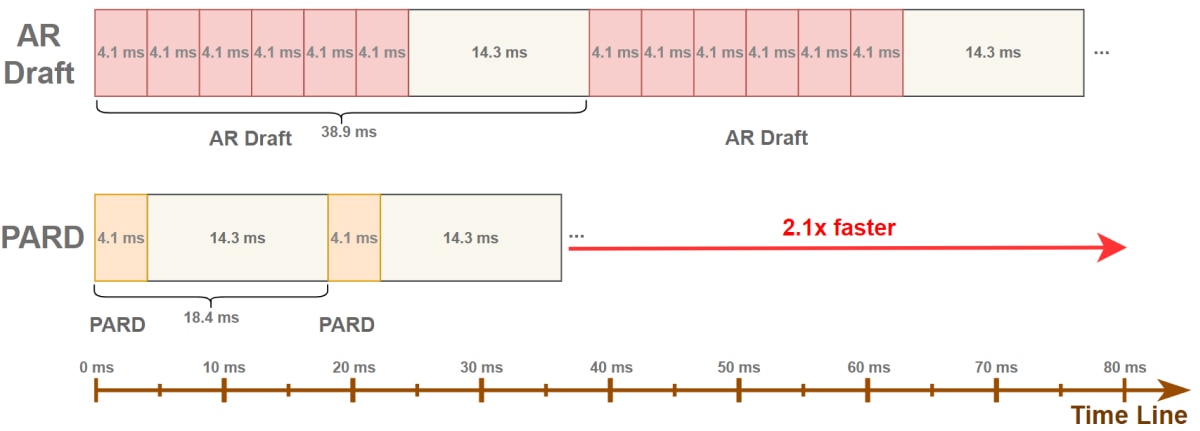
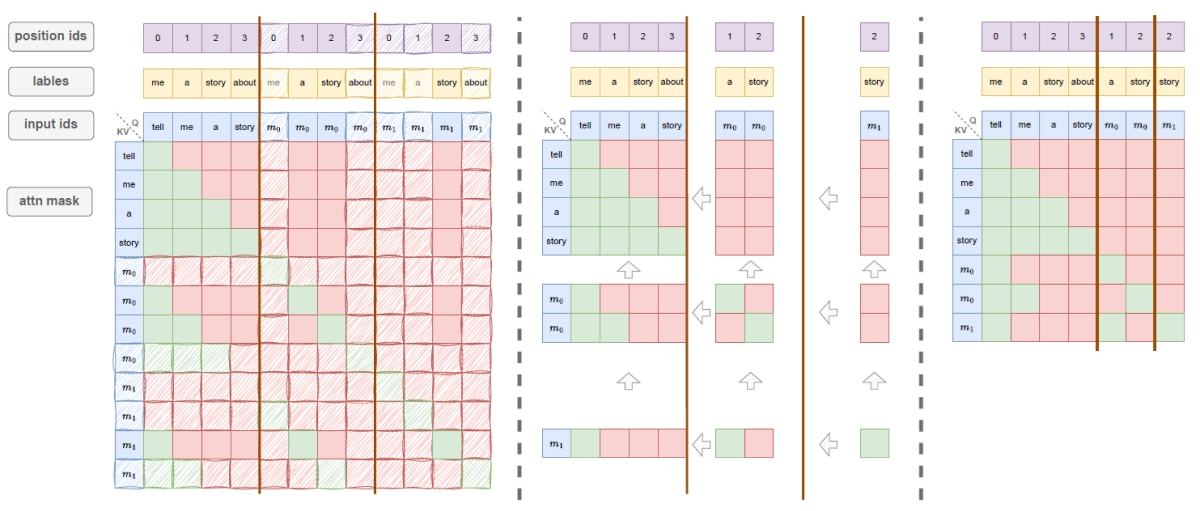
As illustrated in Figure 2, the timeline comparison between PARD and traditional AR models clearly shows that PARD substantially reduces the draft model’s processing time. Since AR models are restricted to predicting the next token, we introduce several mask tokens as padding after the base input tokens in Figure 3. This modification allows the model to predict multiple upcoming tokens in a single forward pass. PARD is a target-independent approach, during inference without relying on target model parameters or hidden states.
PARD Training
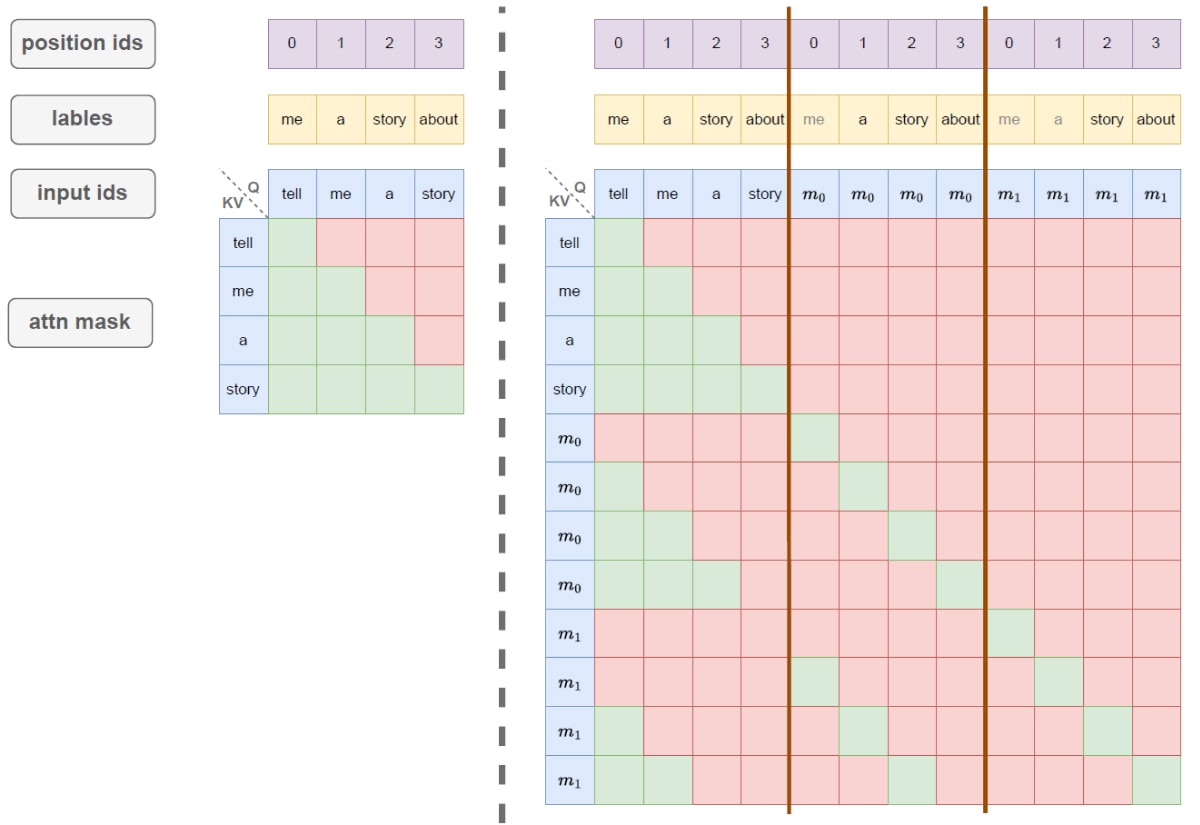
To enable the model to predict multiple subsequent tokens during inference as depicted in Figure 4. The training process is divided into several subtasks. Each subtask corresponds to predicting the next-k token. The designed attention mask ensures consistency between training and inference.
Efficient PARD Training by Conditional Drop: Training the PARD model involves breaking it down into multiple subtasks. In theory, this increases training costs by a factor equal to the number of predicted tokens. For example, predicting eight tokens would make training eight times more expensive than the AR approach. To address this, we introduce a conditional drop strategy (Figure 5). This method selectively omits certain tokens based on their importance. As a result, training speed improves by 3× while maintaining nearly the same performance.
Evaluation
Performance and Deployment: for ease of adoption, we have integrated our inference code within the Transformers framework. By harnessing the power of torch.compile and optimizing KV-cache management, we have significantly enhanced inference speed. This enhanced solution referred to as Transformers+ can be seamlessly deployed as a plugin to the standard Transformers library. All evaluations were conducted using Transformers+ on 1x AMD Instinct MI250.
We evaluated the acceleration performance on the MATH-500, HumanEval, and GSM8K benchmarks, selecting Llama3 (L3), DeepSeek-R1-Qwen (DSR), and Qwen (Q) as target models. The evaluation was performed using a chain decoding structure with a temperature setting of 0. The results showed:
- LlamaA 3 series achieved 2.33× to 2.89× speedup
- DeepSeek-R1-Qwen series achieved 2.3× to 2.8× speedup
- Qwen series achieved 2.75× to 4.77× speedup
Target Model |
Draft Model |
Method |
MATH500 |
HumanEval |
GSM8k |
Average |
L32 3B |
L32 1B |
AR Draft |
1.39 |
1.45 |
1.33 |
1.39 |
L32 3B |
L32 1B PARD |
PARD |
2.32 |
2.54 |
2.14 |
2.33 |
L31 8B |
L32 1B |
AR Draft |
2.01 |
2.13 |
1.99 |
2.04 |
L31 8B |
L32 1B PARD |
PARD |
2.69 |
3.30 |
2.68 |
2.89 |
DSR 7B |
DSR 1.5B |
AR Draft |
1.40 |
1.29 |
1.41 |
1.37 |
DSR 7B |
DSR 1.5B PARD |
PARD |
2.56 |
1.98 |
2.36 |
2.30 |
DSR 14B |
DSR 1.5B |
AR Draft |
2.17 |
1.89 |
2.21 |
2.09 |
DSR 14B |
DSR 1.5B PARD |
PARD |
3.26 |
2.30 |
2.85 |
2.80 |
Q2 7B |
Q2.5 0.5B |
AR Draft |
1.89 |
1.99 |
1.93 |
1.93 |
Q2 7B |
Q2.5 0.5B PARD |
PARD |
2.74 |
3.49 |
2.99 |
3.07 |
Q2.5 1.5B |
Q2.5 0.5B |
AR Draft |
1.14 |
1.11 |
1.16 |
1.14 |
Q2.5 1.5B |
Q2.5 0.5B PARD |
PARD |
2.72 |
2.78 |
2.74 |
2.75 |
Q2.5 3B |
Q2.5 0.5B |
AR Draft |
1.55 |
1.50 |
1.61 |
1.55 |
Q2.5 3B |
Q2.5 0.5B PARD |
PARD |
2.94 |
3.50 |
3.43 |
3.29 |
Q2.5 7B |
Q2.5 0.5B |
AR Draft |
2.29 |
2.09 |
2.31 |
2.23 |
Q2.5 7B |
Q2.5 0.5B PARD |
PARD |
3.84 |
4.30 |
4.48 |
4.21 |
Q2.5 14B |
Q2.5 0.5B |
AR Draft |
3.37 |
3.19 |
3.53 |
3.36 |
Q2.5 14B |
Q2.5 0.5B PARD |
PARD |
4.31 |
4.87 |
5.12 |
4.77 |
Q2.5 7B 1M |
Q2.5 0.5B |
AR Draft |
2.24 |
2.08 |
2.39 |
2.24 |
Q2.5 7B 1M |
Q2.5 0.5B PARD |
PARD |
3.66 |
3.76 |
4.16 |
3.86 |
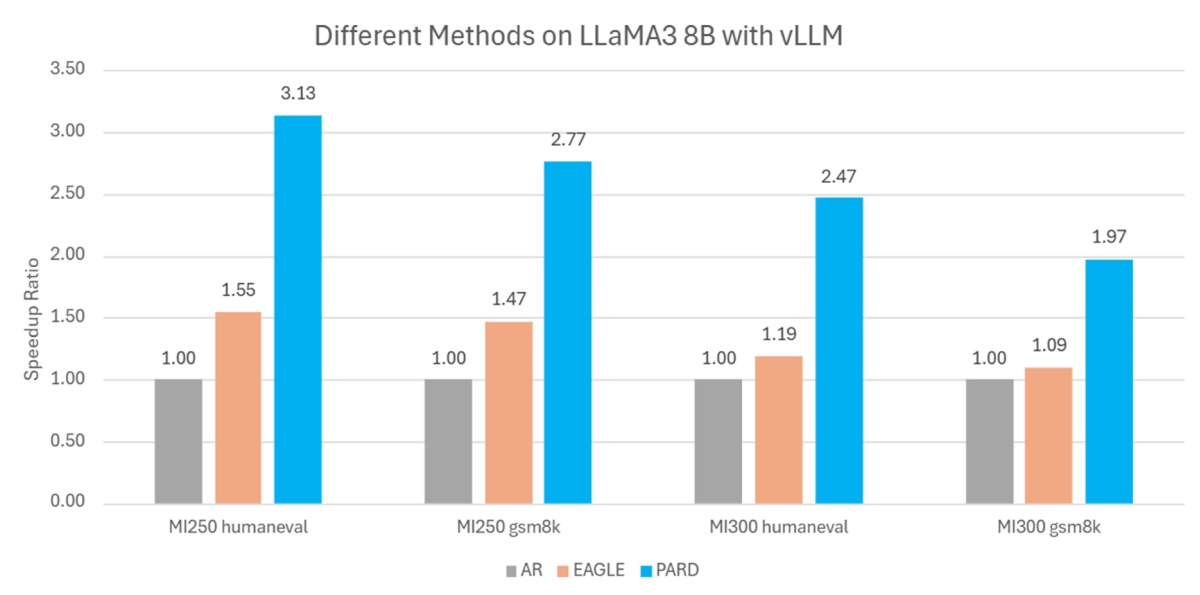
vLLM Integration and Comparison with EAGLE: We integrated PARD into the mainstream inference framework VLLM and compared its performance with the leading academic method EAGLE. For the LLaMA3 8B model, PARD achieved 1.97 ~ 2.77× speedup[4][5] on the GSM8K task and 2.47 ~ 3.13× speedup[4][5] on the HumanEval task, as shown in Figure 6.
Conclusion
We introduce PARD, a novel speculative decoding framework that adapted the vanilla draft model into a parallelized version, dramatically boosting autoregressive generation speed. Our approach features a conditional drop token strategy that accelerates training by over 3 times. Furthermore, PARD proves to be remarkably versatile, delivering consistent performance gains across diverse model families such as Llama3, DeepSeek-R1, and Qwen. Overall, PARD emerges as a robust and practical solution for high-performance language model inference.


Footnotes
- On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), the Llama3 series models achieve up to 3.3× inference speedup. Testing done by AMD on 03/17/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.2
- On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), the DeepSeek series models achieve up to 2.3× inference speedup. Testing done by AMD on 03/17/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.2
- On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), the Qwen model series benefit from a 4.87× inference speedup. Testing done by AMD on 03/17/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.2
- On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), llama3 8B achieved 2.77× speedup on the GSM8K task and 3.13× speedup on the GSM8K task. Testing done by AMD on 04/1/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.1
VLLM Version: base on 0.8.0rc1+rocm631
- On average, a system configured with an AMD Instinct™ MI300X GPU shows that with Parallele Draft (PARD), llama3 8B achieved 1.97× speedup on the GSM8K task and 2.47× speedup on the GSM8K task. Testing done by AMD on 04/15/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS -8125GS-TNMR2
CPU: AMD EPYC 9575F 64-Core Processor (2 sockets, 64 cores per socket, 1 thread per core)
NUMA Config: 1 NUMA node per socket
Memory: 2.21TB
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZ1L2960HCJR-00A07
4 x 3.5T SAMSUNG MZQL23T8HCLS-00A07
GPU: 8x AMD MI300X 192GB HBM3 750W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 3.2
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCmTM 6.3.1
VLLM Version: base on 0.8.0rc1+rocm631
Footnotes
- On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), the Llama3 series models achieve up to 3.3× inference speedup. Testing done by AMD on 03/17/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.2 - On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), the DeepSeek series models achieve up to 2.3× inference speedup. Testing done by AMD on 03/17/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.2 - On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), the Qwen model series benefit from a 4.87× inference speedup. Testing done by AMD on 03/17/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.2 - On average, a system configured with an AMD Instinct™ MI250X GPU shows that with Parallele Draft (PARD), llama3 8B achieved 2.77× speedup on the GSM8K task and 3.13× speedup on the GSM8K task. Testing done by AMD on 04/1/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS - 4124GQ-TNMI
CPU: AMD EPYC 73F3 16-Core Processor (2 sockets, 16 cores per socket, 2 threads per core)
NUMA Config: 2 NUMA node per socket
Memory: 1024 GB (16 DIMMs, 3200 MT/s, 64 GiB/DIMM)
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZQL2960HCJR-00A07
4 x 7T SAMSUNG MZQL27T6HBLA-00A07
GPU: 4x AMD MI250X 128GB HBM2e 500W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 2.5
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCm™ 6.3.1
VLLM Version: base on 0.8.0rc1+rocm631 - On average, a system configured with an AMD Instinct™ MI300X GPU shows that with Parallele Draft (PARD), llama3 8B achieved 1.97× speedup on the GSM8K task and 2.47× speedup on the GSM8K task. Testing done by AMD on 04/15/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro GPU A+ Server AS -8125GS-TNMR2
CPU: AMD EPYC 9575F 64-Core Processor (2 sockets, 64 cores per socket, 1 thread per core)
NUMA Config: 1 NUMA node per socket
Memory: 2.21TB
Disk: Root drive + Data drive combined:
2 x 894.3G SAMSUNG MZ1L2960HCJR-00A07
4 x 3.5T SAMSUNG MZQL23T8HCLS-00A07
GPU: 8x AMD MI300X 192GB HBM3 750W
Host OS: Ubuntu 22.04.5 LTS 5.15.0-41-generic
System BIOS: 3.2
System Bios Vendor:American Megatrends International, LLC.
Host GPU Driver: ROCmTM 6.3.1
VLLM Version: base on 0.8.0rc1+rocm631