AMD Nitro Diffusion: One-Step Text-to-Image Generation Models
Nov 21, 2024
Overview
Recent advancements in generative AI research have revolutionized the field of image generation and visual content creation, marked by significant breakthroughs in both quality and versatility. Various algorithms have been proposed to solve this problem, including Generative Adversarial Networks (GANs)1 and Variational Autoencoders (VAEs)2. Diffusion models have emerged as a leading technique in image generation, demonstrating impressive capabilities such as text-to-image synthesis, image-to-image transformation, and image inpainting3, 4, 5. Together, these advancements not only push the boundaries of artistic and practical applications but also pave the way for new possibilities in fields ranging from entertainment to scientific visualization.
Streamlining Diffusion Models for Efficient Image Generation
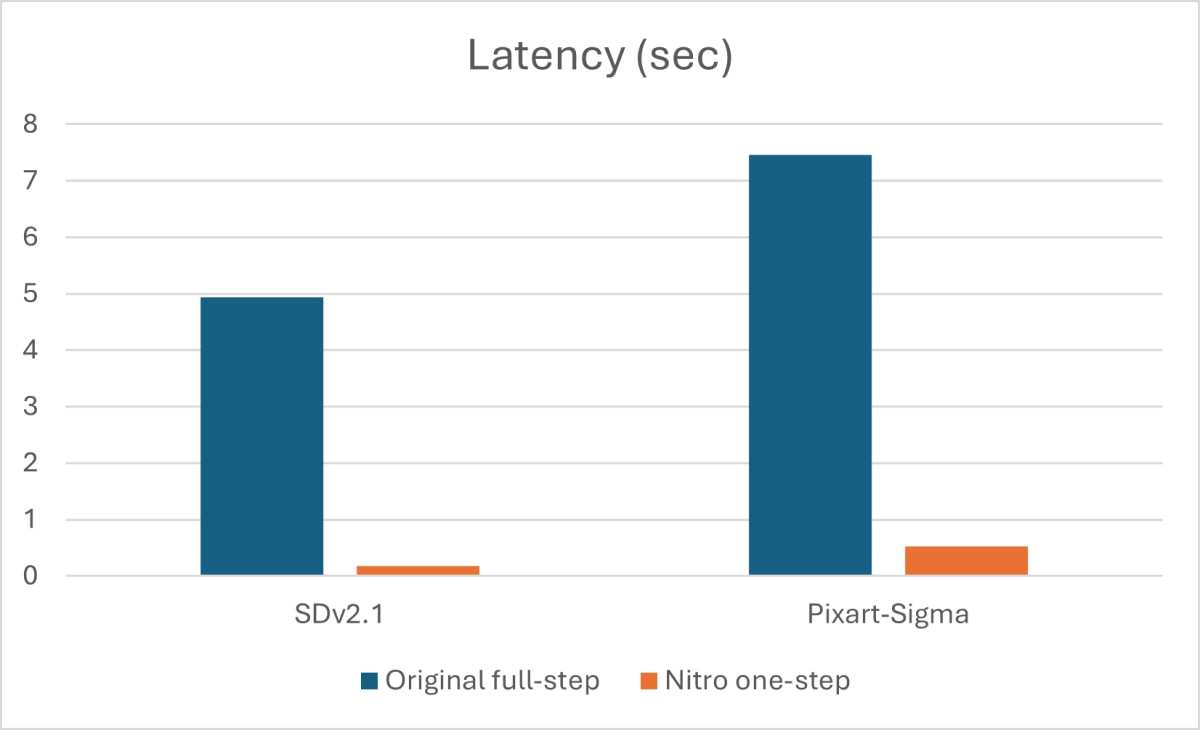
Despite their effectiveness, diffusion models are highly resource-intensive during inference due to their iterative denoising process and complex architectures, which often involve billions of parameters. Popular diffusion models, like Stable Diffusion, require around 20-50 steps to generate a single image3. Through the process of distillation, it is possible to create a model that can produce a similar image in just 1-8 steps, as depicted in the figure below. Since each step involves a full forward pass through a large network, the smaller number of steps results in significantly lower model FLOPS and 60-95% lower inference latency6, 7.
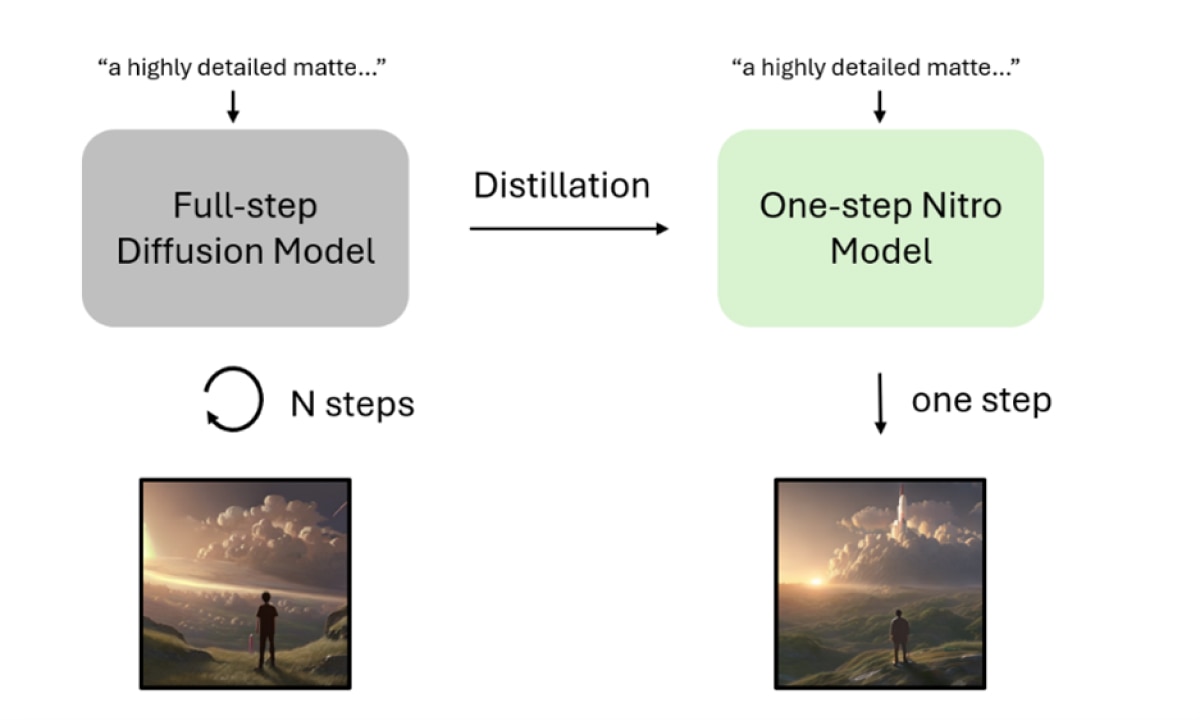
AMD Nitro Diffusion Models
To demonstrate the readiness of AMD Instinct™ MI250 accelerators for model training, and to build a base for further research, AMD is publishing two single-step diffusion models: Stable Diffusion 2.1 Nitro, distilled from the popular Stable Diffusion 2.1 model, and PixArt-Sigma Nitro, distilled from the high resolution PixArt-Sigma model8. These two models generate images in a single forward pass as opposed to the multiple forward passes required by their teacher models, resulting in 90%+ reduction in model FLOPS for only a small loss in image quality.
Our method for distilling these models is an amalgamation of several state-of-the-art methods and roughly reproduces Latent Adversarial Diffusion Distillation9, the method used to create the popular Stable Diffusion 3 Turbo model.
We are also releasing our models and code to the open-source community. Since the original authors of adversarial diffusion distillation did not release a working implementation to the public, we believe this release will help advance further research in the field.
Technical Deep Dive
Base Models
The Stable Diffusion series of open-source models are popular choices for image generation tasks. These models use a UNet architecture as the diffusion backbone along with a CLIP model as the text encoder. We adopted Stable Diffusion 2.1 as the base model to build our UNet-based single-step model.
The PixArt series of models also achieves impressive image generation quality, especially at higher resolutions. PixArt models use a Diffusion Transformer (DiT)10 as the backbone, which offers better flexibility for conditioning and performs better with scale. The models also use the larger T5 text encoder to enable better text understanding. We adopted PixArt-Sigma as the base model to build our higher resolution transformer-based single-step model.
Latent Adversarial Diffusion Distillation
Adversarial training has been a well-studied and effective approach to train GAN image generators, which involves joint training of two models: a discriminator to determine if a generated sample is real or fake and a generator to generate samples that appear indistinguishable from real data to the discriminator. Training a large model from scratch in an adversarial manner is challenging due to its instability and being prone to mode collapse. However, it has been shown that finetuning a pre-trained diffusion model with a discriminator6 is effective, especially for distilling a diffusion model into a few-step or even single-step GAN model.
We adopted this approach and imposed an adversarial loss to encourage the single-step model’s outputs to follow a similar distribution as the base model’s outputs. We initialized the discriminator with the architecture and weights of the base model’s UNet or DiT backbone and attached learnable heads to the intermediate outputs of this frozen backbone. This allowed us to efficiently reuse the features learned by the backbone during pre-training. Another benefit of this design is that both the discriminator and the generator are defined in latent space rather than pixel space, thus avoiding the need to decode the latents using the VAE decoder and significantly reducing the memory required to apply the adversarial loss.
Figure 2 shows the distillation pipeline consisting of: synthetic data generation and joint adversarial training of the model and a latent-space discriminator.
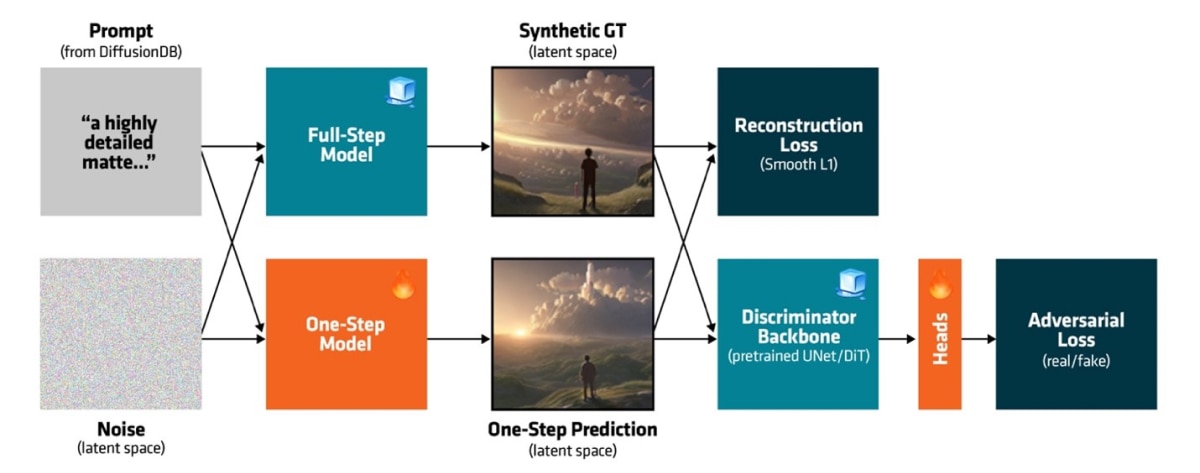
Synthetic Data
Our goal is to make the distilled model outputs as close to the base model outputs as possible. Therefore, instead of using an external dataset to finetune the model, we generated synthetic data using the base model directly as the ground-truth. We extracted 1M prompts from DiffusionDB,11 a large dataset of real prompts generated by users of image generation apps, to generate 1M synthetic images using the base models we want to distill.
Noise-Image Paired Dataset and Reconstruction Losses
The adversarial objective helped shape the distribution of the distilled model outputs closer to that of the base model. To assist the generator to better establish mappings from the noise distribution to the image distribution, we distilled the models using an extra reconstruction loss computed on the noise-image pairs. Specifically, given a target latent image and the corresponding initial noise used by the base model to generate the latent image, we let the model learn to reconstruct the target latent image from the noise. We observed that the added reconstruction loss results in a more stable distillation process.
We explored several reconstruction losses, including simple L1 and L2 losses, the LPIPS perceptual loss in pixel space, SSIM loss in latent space, and Laplacian Pyramid loss. We also re-implemented the latent space perceptual loss LatentLPIPS introduced in a recent paper12. While LatentLPIPS gave us marginal improvements in image quality, we did not see enough improvements using these perceptual losses to justify the added computation. Therefore, we kept it simple and adopted Smooth L1 as the reconstruction loss.
Zero Terminal SNR
As described in "Common Diffusion Noise Schedules and Sample Steps are Flawed,"13 common diffusion noise schedulers are flawed, meaning that even the very last timestep (t=999) has a non-zero signal-to-noise ratio (SNR), implying information leak of the image, and causing inconsistency between the noise levels seen in training and inference. For single-step generation, this issue is more serious since the model takes only a single step without the chance for iterative refinement. We modified the noise scheduler to enforce zero terminal SNR which ensures that the image is generated from pure noise, both in training and inference.
Implementation Details
Our distillation pipeline is implemented in PyTorch which runs seamlessly out-of-the-box on AMD Instinct accelerators. We used the Hugging Face Accelerate library to access advanced training features like mixed-precision training, Fully Sharded Data Parallel (FSDP), and gradient accumulation. The resulting model checkpoints are compatible with standard Diffusers pipelines to enable ease-of-use.
Since our distillation process occurs entirely in the diffusion model’s latent space, we precompute the latent representations of the generated images as well as the text embeddings of the prompts prior to training to avoid having to run the VAE or text encoder during training. This substantially improves training throughput, and the preprocessing cost is amortized over multiple experiments.
Results
Visual Comparison
In this blog, we provide visual results for readers to compare the AMD Nitro models with the base full-step versions. All images were generated on AMD Instinct MI250 accelerator with ROCm™ software 6.1.3.
Prompt
Mountain pine forest with old stone and build a lighthouse in the middle of the mountains, small river flowing through town, daytime, full moon in the sky, hyper realistic, ambient lighting, concept art, intricate, hyper detailed, smooth, dynamic volumetric lighting, octane, raytrace, cinematic, high quality, high resolution
Image Zoom

Image Zoom

Image Zoom

Prompt
A highly detailed matte painting of a man on a hill watching a rocket launch in the distance by studio ghibli, makoto shinkai, by artgerm, by wlop, by greg rutkowski, volumetric lighting, octane render, 4 k resolution, trending on artstation, masterpiece | hyperrealism | highly detailed | insanely detailed | intricate | cinematic lighting | depth of field.
Image Zoom

Image Zoom

Image Zoom

Prompt
Futuristic lighthouse, flash light, hyper realistic, epic composition, cinematic, landscape vista photography, landscape veduta photo & tdraw, detailed landscape painting rendered in enscape, miyazaki, 4k detailed post processing, unreal engineered
Image Zoom

Image Zoom

Image Zoom

Prompt
Photo of a ultra realistic sailing ship, dramatic light, pale sunrise, cinematic lighting, battered, low angle, trending on artstation, 4k, hyper realistic, focused, extreme details, unreal engine 5, cinematic, masterpiece, art by studio ghibli, intricate artwork by john william turner
Image Zoom

Image Zoom

Prompt
Cute toy owl made of suede, geometric accurate, relief on skin, plastic relief surface of body, intricate details, cinematic
Image Zoom

Image Zoom

Prompt
A highly detailed matte painting of a man on a hill watching a rocket launch in the distance by studio ghibli, makoto shinkai, by artgerm, by wlop, by greg rutkowski, volumetric lighting, octane render, 4 k resolution, trending on artstation, masterpiece | hyperrealism | highly detailed | insanely detailed | intricate | cinematic lighting | depth of field.
Image Zoom

Image Zoom

Prompt
Overwhelmingly beautiful eagle framed with vector flowers, long shiny wavy flowing hair, polished, ultra, detailed vector floral illustration mixed with hyper realism, muted pastel colors, vector floral details in the background, muter colors, hyper detailed ultra intricate overwhelming realism in detailed complex scene with magical fantasy atmosphere, no signature, no watermark
Image Zoom

Image Zoom

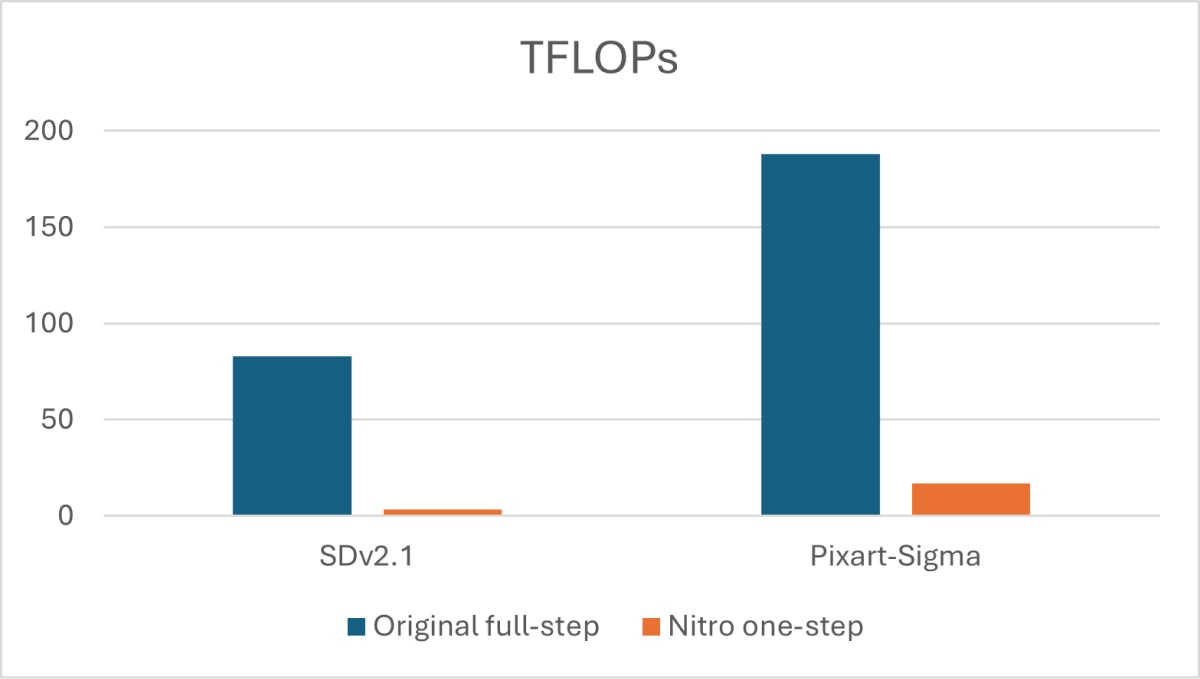
The Result: 90%+ reduction in TFLOPs while maintaining similar image quality.
Compared to Stable Diffusion 2.1, our single-step Stable Diffusion Nitro model achieves a 95.95% reduction in FLOPs at the cost of just 2.5% lower CLIP score and 2.2% higher FID (Figure 2). Compared to the transformer-based PixArt-Sigma model, our single-step PixArt-Sigma Nitro model achieves a 90.93% reduction in FLOPs at the cost of just 3.7% lower CLIP score and 10.56% higher FID (Figure 2). Despite slightly worse scores, our models retain impressive visual quality that is highly competitive with the base models.
These innovations significantly reduce the inference costs of these models and could be meaningful in large-scale serving in data centers or on personalized AI laptops.


Conclusion
We developed our own single-step diffusion models to showcase the capabilities of AMD Instinct accelerators for model training and inference, and to establish a foundation for further research. These models demonstrate performance comparable to full-step diffusion models, while being lightweight enough to run efficiently on both data center systems and edge devices like AI-enabled PCs and laptops. Importantly, to help more developers accelerate their innovation through AMD open software ecosystem, AMD is releasing the models and code to the open-source community, which we believe will contribute to the advancement in generative AI.
Calls to Action
To reproduce the model or run inference on AMD hardware platforms, including Instinct MI250 and MI300x accelerators or Ryzen AI processors, please visit the AMD Hugging Face model cards Stable Diffusion 2.1 Nitro, PixArt-Sigma Nitro for the model files and GitHub repository for the code and instructions. Additionally, we invite developers to leverage the AMD Developer Cloud which provides remote access to select AMD Instinct accelerators. Visit the AMD Developer Cloud sign up page for specific accessing request and instructions.
We welcome your questions and feedback. For further inquiries, please don't hesitate to contact AMD team via email at amd_ai_mkt@amd.com.
References
- Goodfellow, Ian, et al. "Generative adversarial nets." Advances in neural information processing systems 27 (2014).
- Kingma, Diederik P. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).
- Podell, Dustin, et al. "Sdxl: Improving latent diffusion models for high-resolution image synthesis." arXiv preprint arXiv:2307.01952 (2023).
- Saharia, Chitwan, et al. "Photorealistic text-to-image diffusion models with deep language understanding." Advances in neural information processing systems 35 (2022): 36479-36494.
- Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
- Sauer, Axel, et al. "Adversarial diffusion distillation." European Conference on Computer Vision. Springer, Cham, 2025.
- Luo, Simian, et al. "Latent consistency models: Synthesizing high-resolution images with few-step inference." arXiv preprint arXiv:2310.04378 (2023).
- Chen, Junsong, et al. "Pixart-\sigma: Weak-to-strong training of diffusion transformer for 4k text-to-image generation." arXiv preprint arXiv:2403.04692 (2024).
- Sauer, Axel, et al. "Fast high-resolution image synthesis with latent adversarial diffusion distillation." arXiv preprint arXiv:2403.12015 (2024).
- Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
- Wang, Zijie J., et al. "Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models." arXiv preprint arXiv:2210.14896 (2022).
- Kang, Minguk, et al. "Distilling diffusion models into conditional gans." European Conference on Computer Vision. Springer, Cham, 2025.
- Lin, Shanchuan, et al. "Common diffusion noise schedules and sample steps are flawed." Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2024.
Configuration details:
MI250 Claims: https://www.amd.com/en/products/accelerators/instinct/mi200.html
Ryzen AI Claims: https://www.amd.com/en/products/processors/consumer/ryzen-ai.html
