AMD Hummingbird-0.9B: An Efficient Text-to-Video Diffusion Model with 4-Step Inferencing
Feb 28, 2025
Introduction
Text-to-video (T2V) generation excels in creating realistic and dynamic videos from text, becoming a hot AI topic with high commercial value for many industries. However, developing a T2V diffusion model remains a challenge due to the necessity of balancing computational efficiency and visual performance. Most current research focuses on improving visual performance while overlooking model size and inference speed, which are crucial for deployment.
To address this challenge, AMD AI research team proposed reducing the model parameters while boosting the visual performance through a two-stage fine-tuning distillation and reward model optimization. This approach cuts the model parameters from 1.4 billion, as seen in the widely used VideoCrafter21 model, to 0.945 billion, the size of AMD diffusion model, enabling high-quality video generation with minimal inference steps. As shown in this blog, the proposed AMD Hummingbird-0.9B T2V diffusion model achieves approximately 23x lower latency compared to VideoCrafter2 on AMD Instinct™ MI250 accelerators. In addition, running the same model on a consumer laptop (iGPU: RadeonTM 880M, CPU: Ryzen™ AI 9 365) was able to generate a video in 50 seconds1. Pioneering structural distillation for T2V diffusion models, AMD also introduced a new data processing pipeline for high-quality visual and textual data for model training, demonstrating significant progress of AMD in AI-driven video generation.
Why Build AMD Own Text-to-Video (T2V) Model?
The development of this T2V model is driven by several key factors.
Firstly, efficiency plays a crucial role. Existing open-source T2V models like VideoCrafter22 and CogVideo3 have made significant strides in visual performance, but they do not yet achieve efficient generation on typical GPUs. There is a critical need for smaller models that align with operational constraints while maintaining high performance.
Another important consideration is model size and inference speed. Most current research emphasizes improving visual performance, often at the expense of model size and inference speed, which are crucial for practical deployment. AMD approach focuses on balancing these aspects to ensure both high-quality outputs and efficient operations.
Customization is also a key advantage of building our own model. The proposed structural distillation method allows for adaptable and reward-optimized models, providing users with tailored solutions that meet their specific needs.
Data quality is essential for effective model learning. This novel data processing pipeline helps ensure that the model is trained on top-quality visual and textual data, enhancing its performance and reliability. High-quality training data is critical for the model to generate richer textural details and better understand textual input.
Finally, by open sourcing the training code, dataset, and model weights, AMD supports the AI community. This enables developers to replicate and explore T2V generation on AMD AI platforms, fostering an open and collaborative approach to AI development, and ensuring that the benefits of AI advancements are widely shared.
AMD Hummingbird-0.9B Text-to-Video Diffusion Model
With the above considerations, AMD research team proposed an efficient T2V model along with a training pipeline. This pipeline is designed to be user-friendly, allowing users to build their own models and achieve exceptional performance. Additionally, the style of the generated videos can vary significantly based on the training data. If users wish to generate videos with a specific style, it is recommended using the video data that reflects the desired style.
In specific, there are two key techniques to develop an efficient T2V diffusion model: (1) A data processing pipeline; (2) An innovative model distillation method.
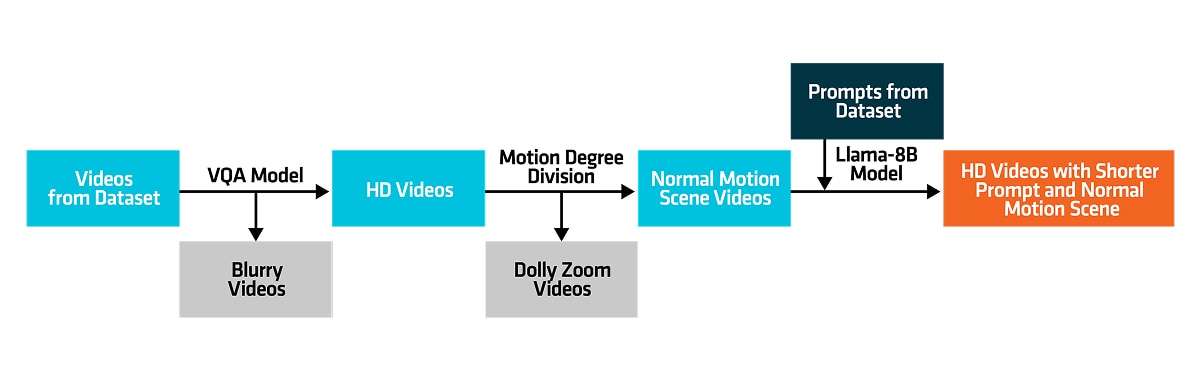
Data processing includes video quality assessment, motion estimation, and prompts re-captioning. Low-quality video data slows loss function convergence during training and reduces performance of the T2V diffusion model. The new data processing pipeline proposed by AMD begins with Video Quality Assessment (VQA) models4 to evaluate video quality scores, including aesthetics and compression metrics, as shown in figure 1. Then, a motion estimation module filters out dolly zoom videos from the remaining high-quality ones. For improved textual input quality, it leverages the prior knowledge of a multimodal model (Llama-8B)5 for text re-captioning. Experiments demonstrated that using high-quality videos, both visually and textually, enables the T2V diffusion model to generate richer textural details and better understand textual input.
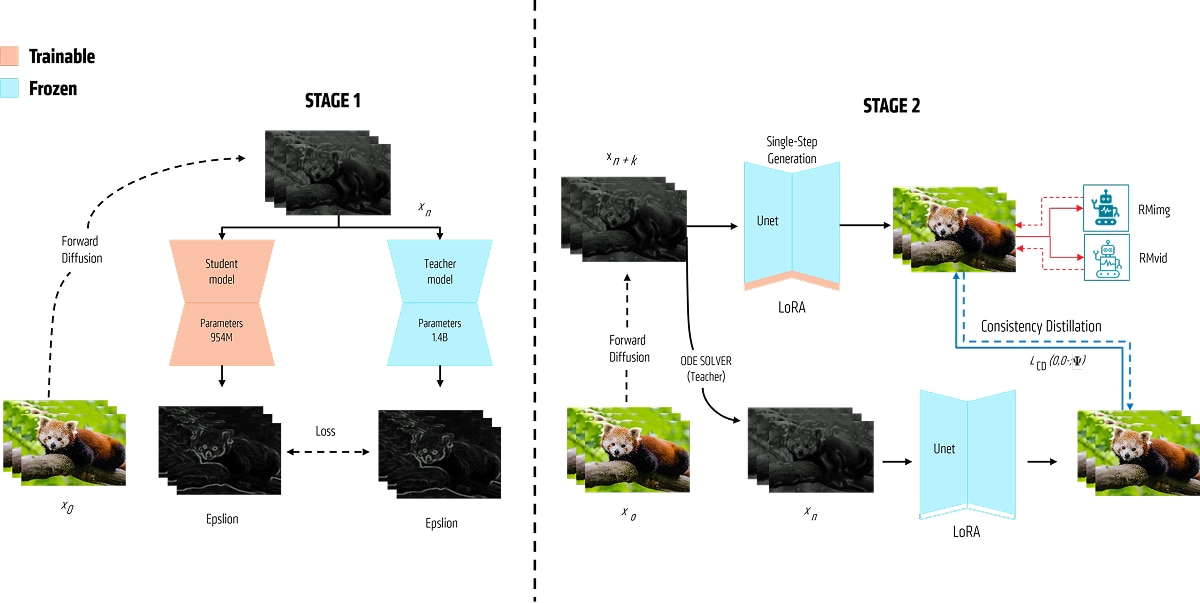
Model distillation helps reduce model parameters for deployment, but it has not been applied to Text-to-Video diffusion models. The key challenge is transferring the knowledge from the original model to a smaller model. To solve this, AMD proposed a two-stage distillation method.
First Stage: the initial step includes creating a smaller model by halving the number of blocks in each layer. It is crucial to preserve structural similarity with the original model while cutting down the blocks, as many experiments have confirmed that this similarity aids prior adaptation and cuts down training time significantly.
Taking VideoCrafter2 with 1.4 billion parameters as an example, the parameters of the reconstruct model are reduced to 0.945 billion. We then use the outputs of the original model as supervision to fine-tune the smaller model. It is observed that the training loss converges quickly due to the similar structure. To further speed up the training process, two empirical acceleration methods are employed: (1) directly learn the video results after classifier-free guidance (CFG) from the original model, and (2) inspired by Consistency Models, we minimize the difference between pairs of adjacent points on a Probability Flow Ordinary Differential Equation (PF ODE) trajectory using numerical ODE solvers. As a result of these methods, the first-stage training takes only one GPU-day on eight AMD Instinct™ MI250 GPUs with 64 GB of memory each.
Second Stage: the next step is to further refine the visual performance of the AMD Hummingbird-0.9B T2V diffusion model by improving aspects like tonal range, deep saturation, finer textural details, and vivid colors. One direct approach would be to collect or synthesize additional video data that showcases appealing visual effects (VFX). For instance, some methods capture video clips from movies and use them as high-quality training data, given their production with advanced cameras and thorough post-production. However, data collection requires substantial time and resources. Additionally, downloading extra data consumes more bandwidth and increases waiting times.
This motivated us to develop a method to reuse first-stage training data for better visual performance. Inspired by T2V-turbo6,7, we use reward feedback from a mixture of reward models to gradually extract valuable information from sampled video data by extracting relevant visual information from the existing video data. To improve temporal dynamics and transitions in generated videos, we employ both image-text and video-text reward models. The second-stage training also requires only one GPU-day on eight MI250 GPUs with 64 GB of memory each.
AMD Hummingbird-0.9B Training Details
Training Dataset
The WebVid-10M8 dataset is used to train the text-to-video diffusion model. A portion of the high-quality video data is selected using a proposed data processing method for the first-stage training. For the second-stage training, a subset is randomly sampled from this selection.
Training Hardware and Software:
The training was conducted on AMD Instinct™ MI250 accelerator, CDNA™ 2, 362.1 TFLOPs FP16 peak theoretical performance, 128GB HBM2e, 3.2 TB/s peak memory bandwidth, 500W; and with Python 3.8, ROCm™ software 5.6.0, PyTorch 2.2.0, and FlashAttention 2.2.0.
Performance Comparison: Enhanced Visual Quality and ~23X Lower Latency
Why 4-Step Inferencing?
Before validating the AMD Hummingbird-0.9B diffusion model against other diffusion models in terms of the visual performance and inference speed, the AMD research team conducted an experiment to examine the latency by using different inference steps. The visual performance and inference speed under different inference steps are shown as below:
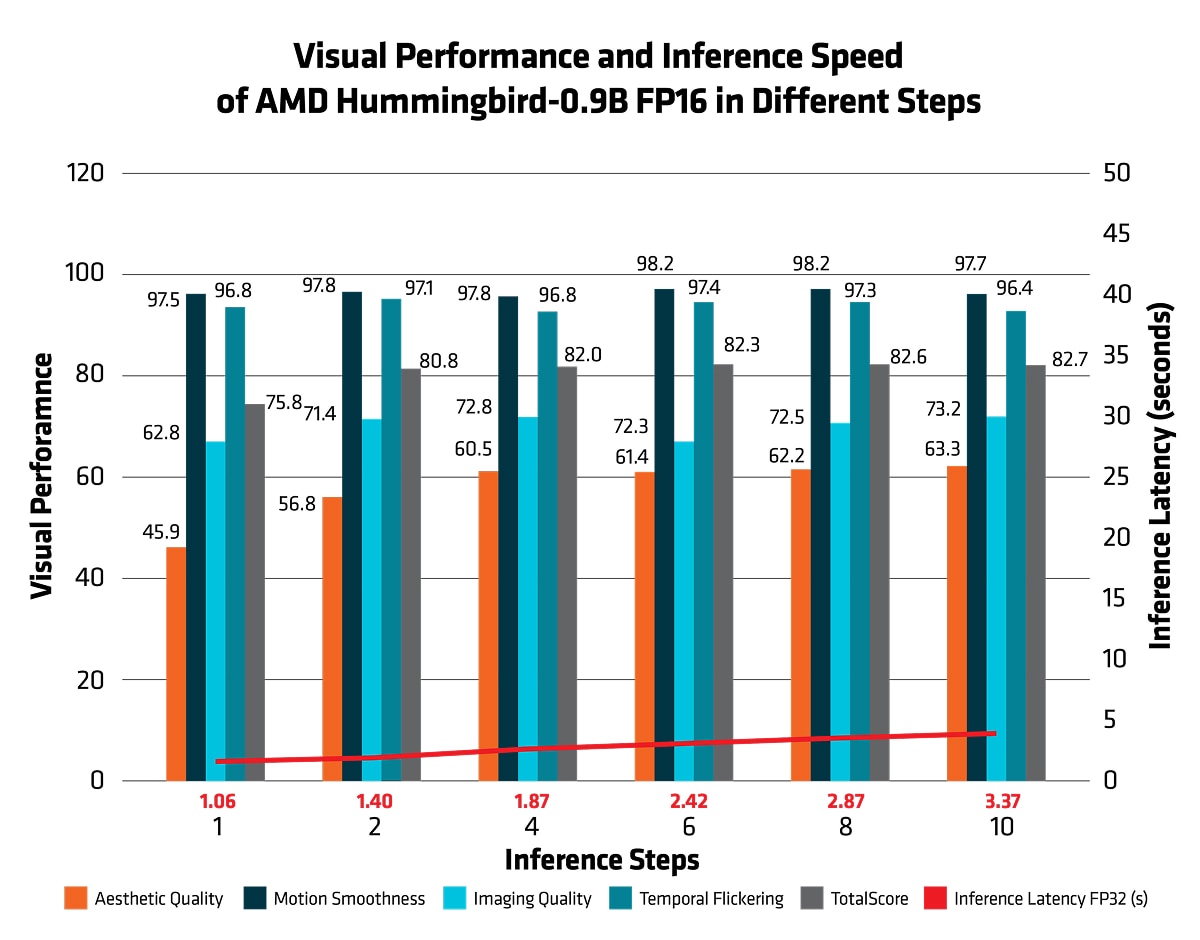
From figures 3, it can be concluded that the visual performance and inference latency of the AMD Hummingbird-0.9B model vary depending on the number of inference steps. For faster inference, using 4 steps is recommended, while 8 steps provide improved visual quality. However, increasing the inference steps further will result in higher inference latency therefore is not advised.
Performance Comparison with Other Diffusion Models
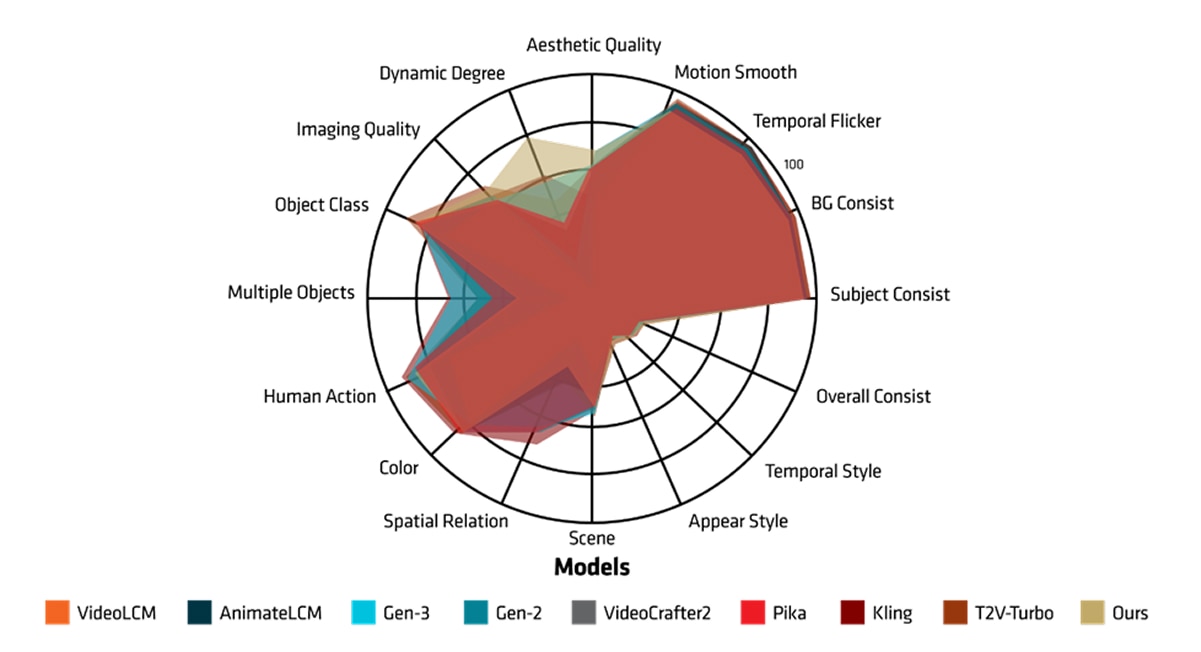
To assess the visual performance of Hummingbird-0.9B in further, AMD research team compared it against larger foundation models—VideoCrafter2, animateLCM and VideoLCM, using text prompts from Vbench. These prompts include scenarios featuring natural landscapes, science fiction settings, and urban environments. From Table 1, AMD Hummingbird-0.9B model, despite its smaller size, showcased comparable aesthetic quality, motion smoothness, imaging quality, and temporal flickering etc., achieving a total performance score that is on par with its larger counterparts (VideoCrafer2). This demonstrates the model's efficiency and capability in generating high-quality visuals even with fewer parameters and computational resources. Figure 4 shows that the AMD Hummingbird-0.9B model demonstrates performance comparable to closed-source T2V models like Kling and Pika, except in the areas of Spatial Relation, Multiple Objects, and Human Action. Further improvements in these evaluation dimensions are expected by incorporating higher-quality training data.
Model |
Steps |
Param. |
Subject Consist. |
BG Consist. |
Temporal Flicker. |
Motion Smooth. |
Aesthetic Quality |
Dynamic Degree |
Image Quality |
Object Class |
Total Score |
VideoLCM9 |
4 |
1.4B |
96.55 |
97.23 |
97.33 |
97.01 |
59.93 |
5.56 |
66.43 |
75.40 |
73.27 |
Multiple Class |
Human Action |
Color |
Spatial Relation. |
Scene |
Appear. Style |
Temporal Style |
Overall Consist. |
||||
12.50 |
73.00 |
82.64 |
19.85 |
35.10 |
19.87 |
22.25 |
23.68 |
||||
AnimateLCM10 |
4 |
1.3B |
Subject Consist. |
BG Consist. |
Temporal Flicker. |
Motion Smooth. |
Aesthetic Quality |
Dynamic Degree |
Image Quality |
Object Class |
77.74 |
96.57 |
96.57 |
98.41 |
98.33 |
63.26 |
33.33 |
62.30 |
87.34 |
||||
Multiple Class |
Human Action |
Color |
Spatial Relation. |
Scene |
Appear. Style |
Temporal Style |
Overall Consist. |
||||
34.68 |
83.00 |
85.62 |
40.86 |
46.29 |
19.87 |
24.19 |
25.57 |
||||
VideoCrafter 211 |
50 |
1.4B |
Subject Consist. |
BG Consist. |
Temporal Flicker. |
Motion Smooth. |
Aesthetic Quality |
Dynamic Degree |
Image Quality |
Object Class |
80.44 |
96.85 |
98.22 |
98.41 |
97.73 |
63.13 |
42.50 |
67.22 |
92.55 |
||||
Multiple Class |
Human Action |
Color |
Spatial Relation. |
Scene |
Appear. Style |
Temporal Style |
Overall Consist. |
||||
40.66 |
95.00 |
92.92 |
35.86 |
55.29 |
25.13 |
25.84 |
28.23 |
||||
Hummingbird-0.9B |
4 |
0.9B |
Subject Consist. |
BG Consist. |
Temporal Flicker. |
Motion Smooth. |
Aesthetic Quality |
Dynamic Degree |
Image Quality |
Object Class |
79.89 |
95.53 |
96.31 |
94.83 |
93.93 |
68.43 |
80.56 |
71.17 |
91.53 |
||||
Multiple Class |
Human Action |
Color |
Spatial Relation. |
Scene |
Appear. Style |
Temporal Style |
Overall Consist. |
||||
35.21 |
90.00 |
94.92 |
33.67 |
50.87 |
22.16 |
24.66 |
27.50 |
Table 1: AMD Hummingbird-0.9B Visual Performance Comparison with VideoLCM, AnimateLCM and VideoCrafter2 on Vbench12.
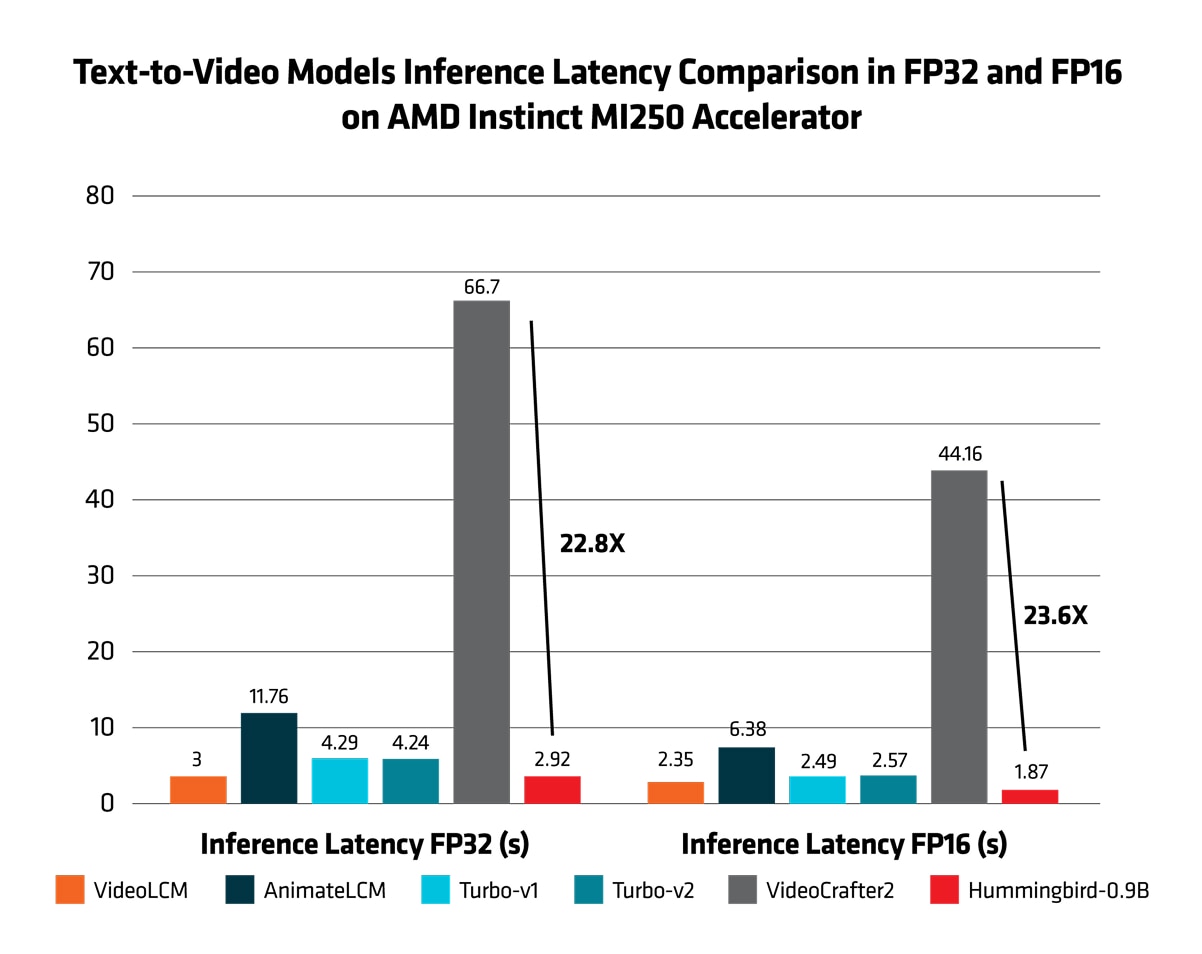
In addition, inference performance was also conducted among these models. Figure 5 showcases the outstanding performance of the AMD Hummingbird-0.9B, achieved ~23X inference speedup compared to VideoCrafter2 on AMD Instinct MI250 accelerator. With impressive speed, efficiency and enhanced visual performance, this model sets a new standard in text-to-video generation, demonstrating significant improvements and capabilities.
To provide clear examples, here is video demonstration showcasing the capability of AMD Hummingbird-0.9B diffusion to generate videos with fine-grained textures and vibrant colors.

Conclusion
The AMD Hummingbird-0.9B T2V diffusion model marks a significant advancement in text-to-video generation, leveraging the capabilities of AMD state-of-the-art hardware and software technologies. The structure distillation method proposed for the T2V diffusion model exemplifies the dedication of AMD to fostering AI innovation, offering exceptional performance and efficiency. Additionally, AMD hardware and software excel in training and inferencing large-scale models like T2V diffusion model, making it a key player in advancing AI and empowering developers to push the boundaries of innovation.
Call to Actions
By open sourcing the training code, dataset, and model weights for the AMD Hummingbird-0.9B T2V diffusion model, we support the AI developer community to accelerate innovation without sacrificing visual performance. You are welcome to download and try this model on AMD platforms. To get more information about the training, inferencing and insights of this model, please visit AMD Github repository to get access to the codes, and visit Hugging Face Model Card to download the model file. As a further benefit, AMD is offering a dedicated cloud infrastructure including the latest GPU instance to AI developers, please visit AMD Developer Cloud for specific accessing request and usage. For any questions, you may reach out to the AMD team at amd_ai_mkt@amd.com.
Additional Resources:
AMD ROCm AI Developer Hub: Access tutorials, blogs, open-source projects, and other resources for AI development with ROCm™ software platform. This site provides an end-to-end journey for all AI developers who want to develop AI applications and optimize them on AMD GPUs.
AMD Model Blogs: Explore various blogs that cover AMD trained models

Fußnoten
- Testing as of Nov 2024 by AMD using AMD Radeon® 880M Ryzen® AI 9 365 Ubuntu 6.8.0-51-generic
- Chen H, Zhang Y, Cun X, et al. Videocrafter2: Overcoming data limitations for high-quality video diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 7310-7320.
- Yang Z, Teng J, Zheng W, et al. Cogvideox: Text-to-video diffusion models with an expert transformer[J]. arXiv preprint arXiv:2408.06072, 2024.
- Wu H, Zhang E, Liao L, et al. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 20144-20154.
- Dubey A, Jauhri A, Pandey A, et al. The llama 3 herd of models[J]. arXiv preprint arXiv:2407.21783, 2024.
- Li J, Long Q, Zheng J, et al. T2v-turbo-v2: Enhancing video generation model post-training through data, reward, and conditional guidance design[J]. arXiv preprint arXiv:2410.05677, 2024.
- Li J, Feng W, Fu T J, et al. T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback[J]. arXiv preprint arXiv:2405.18750, 2024.
- Bain M, Nagrani A, Varol G, et al. Frozen in time: A joint video and image encoder for end-to-end retrieval[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 1728-1738.
- Wang X, Zhang S, Zhang H, et al. Videolcm: Video latent consistency model[J]. arXiv preprint arXiv:2312.09109, 2023.
- Wang F Y, Huang Z, Bian W, et al. Animatelcm: Computation-efficient personalized style video generation without personalized video data[M]//SIGGRAPH Asia 2024 Technical Communications. 2024: 1-5.
- Chen H, Zhang Y, Cun X, et al. Videocrafter2: Overcoming data limitations for high-quality video diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 7310-7320.
- Huang Z, He Y, Yu J, et al. Vbench: Comprehensive benchmark suite for video generative models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 21807-21818.
- Huang Z, He Y, Yu J, et al. Vbench: Comprehensive benchmark suite for video generative models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 21807-21818.
- MI200-94:Testing conducted internally by AMD Research team as of December 2024, on AMD Instinct MI250 accelerator, measuring the latency of AMD Hummingbird-0.9B, VideoLCM, animatedLCM, Turbo-v1, Turbo-v2 and VideoCrafter2, all in FP16, results are an averageof tested 5 rounds.
Test environment:
OS: Ubuntu 22.04 LTS
CPU: AMD EPYC 73F3 CPU x1
GPU: Instinct MI250 GPU x1
GPU Driver: ROCm 6.1
Python 3.8, PyTorch 2.2.0, and FlashAttention 2.2.0.
Inference latency:
VideoLCM = 2.35s
animateLCM = 6.38s
Turbo-v1 = 2.49s
Turbo-v2 = 2.57s
VideoCrafter2 = 44.16s
Hummingbird0.9B = 1.87s
Performance may vary based on different hardware configurations, software versions and optimization.
MI200-94
- MI200-95:Testing conducted internally by AMD Research team as of December 2024, on AMD Instinct MI250 accelerator, measuring the latency of AMD Hummingbird-0.9B, VideoLCM, animatedLCM, Turbo-v1, Turbo-v2 and VideoCrafter2, all in FP32, results are an overage of tested for 5 rounds.
Test environment:
OS: Ubuntu 22.04 LTS
CPU: AMD EPYC 73F3 CPU x1
GPU: Instinct MI250 GPU x1
GPU Driver: ROCm 6.1
Python 3.8, PyTorch 2.2.0, and FlashAttention 2.2.0.
Inference latency:
VideoLCM = 3.00s
animateLCM = 11.76s
Turbo-v1 = 4.29s
Turbo-v2 = 4.24s
VideoCrafter2 = 66.70s
Hummingbird0.9B = 2.92s
Performance may vary based on different hardware configurations, software versions and optimization.
MI200-95
- Text prompts of video 1:
- A 3D model of a 1800s victorian house.
- A drone flying over a snowy forest.
- A quiet beach at dawn and the waves gently lapping.
- A sandcastle being eroded by the incoming tide.
- A cat DJ at a party
- An astronaut flying in space, in cyberpunk style
- A ghost ship navigating through a sea under a moon
- A cute teddy bear, dressed in a red silk outfit, stands in a vibrant street, Chinese New Year.
- A cute raccoon playing guitar in the forest
- A cute raccoon playing guitar at the beach
- A cute happy Corgi playing in park, sunset, animated style.
- A cute happy Corgi playing in park, sunset, pixel
- Text prompts of video 2:
- The girl lovingly plays with the teddy, hugging it tightly. Laughter and warmth fill the air.
- The teddy bear is packed in a cardboard box for ages, its eyes reflecting quiet abandonment and profound loneliness.
- The teddy bear visualizes itself walking down an empty, snow-covered street. The soft, swirling snowflakes seem to mirror its inner sadness, yet it walks with purpose, envisioning a life of independence, free from neglect.
- The teddy bear sits on a cliff, gazing at the starry sky and sunrise, dreaming of hope.
- The teddy bear walks along a quiet beach. The vast ocean stretches out before it, symbolizing freedom, new beginnings, and the endless possibilities ahead.
- The teddy dear walks along the beach, spotting a female teddy bear. Their eyes meet across the shore, an unspoken connection forming as the waves crash softly, signaling the start of love.
- A couple of teddy bears, side by side, bask in happiness. Together a cloud, they smile and laugh, their bond strong, floating joyfully in a world of dreams and love.
- A couple of teddy bears stand side by side, smiling at each other, with a large, colorful balloon floating behind them, symbolizing their shared journey and dreams.
- The female teddy bear stands gracefully, holding a flower in her paw, dressed in a delicate wedding gown.
- The male teddy bear stands confidently, dressed in a formal tuxedo.
- The teddy bear and its baby sit together, sipping tea. A sense of warmth fills the scene.
Fußnoten
- Testing as of Nov 2024 by AMD using AMD Radeon® 880M Ryzen® AI 9 365 Ubuntu 6.8.0-51-generic
- Chen H, Zhang Y, Cun X, et al. Videocrafter2: Overcoming data limitations for high-quality video diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 7310-7320.
- Yang Z, Teng J, Zheng W, et al. Cogvideox: Text-to-video diffusion models with an expert transformer[J]. arXiv preprint arXiv:2408.06072, 2024.
- Wu H, Zhang E, Liao L, et al. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 20144-20154.
- Dubey A, Jauhri A, Pandey A, et al. The llama 3 herd of models[J]. arXiv preprint arXiv:2407.21783, 2024.
- Li J, Long Q, Zheng J, et al. T2v-turbo-v2: Enhancing video generation model post-training through data, reward, and conditional guidance design[J]. arXiv preprint arXiv:2410.05677, 2024.
- Li J, Feng W, Fu T J, et al. T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback[J]. arXiv preprint arXiv:2405.18750, 2024.
- Bain M, Nagrani A, Varol G, et al. Frozen in time: A joint video and image encoder for end-to-end retrieval[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 1728-1738.
- Wang X, Zhang S, Zhang H, et al. Videolcm: Video latent consistency model[J]. arXiv preprint arXiv:2312.09109, 2023.
- Wang F Y, Huang Z, Bian W, et al. Animatelcm: Computation-efficient personalized style video generation without personalized video data[M]//SIGGRAPH Asia 2024 Technical Communications. 2024: 1-5.
- Chen H, Zhang Y, Cun X, et al. Videocrafter2: Overcoming data limitations for high-quality video diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 7310-7320.
- Huang Z, He Y, Yu J, et al. Vbench: Comprehensive benchmark suite for video generative models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 21807-21818.
- Huang Z, He Y, Yu J, et al. Vbench: Comprehensive benchmark suite for video generative models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 21807-21818.
- MI200-94:Testing conducted internally by AMD Research team as of December 2024, on AMD Instinct MI250 accelerator, measuring the latency of AMD Hummingbird-0.9B, VideoLCM, animatedLCM, Turbo-v1, Turbo-v2 and VideoCrafter2, all in FP16, results are an averageof tested 5 rounds.
Test environment:
OS: Ubuntu 22.04 LTS
CPU: AMD EPYC 73F3 CPU x1
GPU: Instinct MI250 GPU x1
GPU Driver: ROCm 6.1
Python 3.8, PyTorch 2.2.0, and FlashAttention 2.2.0.
Inference latency:
VideoLCM = 2.35s
animateLCM = 6.38s
Turbo-v1 = 2.49s
Turbo-v2 = 2.57s
VideoCrafter2 = 44.16s
Hummingbird0.9B = 1.87s
Performance may vary based on different hardware configurations, software versions and optimization.
MI200-94 - MI200-95:Testing conducted internally by AMD Research team as of December 2024, on AMD Instinct MI250 accelerator, measuring the latency of AMD Hummingbird-0.9B, VideoLCM, animatedLCM, Turbo-v1, Turbo-v2 and VideoCrafter2, all in FP32, results are an overage of tested for 5 rounds.
Test environment:
OS: Ubuntu 22.04 LTS
CPU: AMD EPYC 73F3 CPU x1
GPU: Instinct MI250 GPU x1
GPU Driver: ROCm 6.1
Python 3.8, PyTorch 2.2.0, and FlashAttention 2.2.0.
Inference latency:
VideoLCM = 3.00s
animateLCM = 11.76s
Turbo-v1 = 4.29s
Turbo-v2 = 4.24s
VideoCrafter2 = 66.70s
Hummingbird0.9B = 2.92s
Performance may vary based on different hardware configurations, software versions and optimization.
MI200-95 - Text prompts of video 1:
- A 3D model of a 1800s victorian house.
- A drone flying over a snowy forest.
- A quiet beach at dawn and the waves gently lapping.
- A sandcastle being eroded by the incoming tide.
- A cat DJ at a party
- An astronaut flying in space, in cyberpunk style
- A ghost ship navigating through a sea under a moon
- A cute teddy bear, dressed in a red silk outfit, stands in a vibrant street, Chinese New Year.
- A cute raccoon playing guitar in the forest
- A cute raccoon playing guitar at the beach
- A cute happy Corgi playing in park, sunset, animated style.
- A cute happy Corgi playing in park, sunset, pixel
- Text prompts of video 2:
- The girl lovingly plays with the teddy, hugging it tightly. Laughter and warmth fill the air.
- The teddy bear is packed in a cardboard box for ages, its eyes reflecting quiet abandonment and profound loneliness.
- The teddy bear visualizes itself walking down an empty, snow-covered street. The soft, swirling snowflakes seem to mirror its inner sadness, yet it walks with purpose, envisioning a life of independence, free from neglect.
- The teddy bear sits on a cliff, gazing at the starry sky and sunrise, dreaming of hope.
- The teddy bear walks along a quiet beach. The vast ocean stretches out before it, symbolizing freedom, new beginnings, and the endless possibilities ahead.
- The teddy dear walks along the beach, spotting a female teddy bear. Their eyes meet across the shore, an unspoken connection forming as the waves crash softly, signaling the start of love.
- A couple of teddy bears, side by side, bask in happiness. Together a cloud, they smile and laugh, their bond strong, floating joyfully in a world of dreams and love.
- A couple of teddy bears stand side by side, smiling at each other, with a large, colorful balloon floating behind them, symbolizing their shared journey and dreams.
- The female teddy bear stands gracefully, holding a flower in her paw, dressed in a delicate wedding gown.
- The male teddy bear stands confidently, dressed in a formal tuxedo.
- The teddy bear and its baby sit together, sipping tea. A sense of warmth fills the scene.